Tutorium zu sensorielle Panelanalysen in Excel
Dieses Tutorium zeigt Ihnen, wie Sie die Qualität eines sensoriellen Panels in Excel mithilfe der Statistiksoftware XLSTAT evaluieren.
Datensatz für sensorielle Panelanalyse
Die in diesem Tutorium verwendeten Daten entsprechen der Auswertung von 14 verschiedenen Skischuhen durch 15 Skifahrer (hierin bezeichnet als Bewerter) mit Erfahrung in sensoriellen Tests für die Bekleidungsindustrie. 6 Deskriptoren wurden von den 15 Bewertern für die Bewertung der Schuhe verwendet.
Einrichten einer Panelanalyse
Nach dem Aktivieren von XLSTAT wählen Sie den Befehl XLSTAT/Sensorielle Datenanalyse/Panelanalyse (siehe unten) oder klicken Sie auf den entsprechenden Button der Symbolleiste XLSTAT-Sensorielle Datenanalyse.
Nach dem Klicken des entsprechenden Buttons erscheint das Dialogfenster.
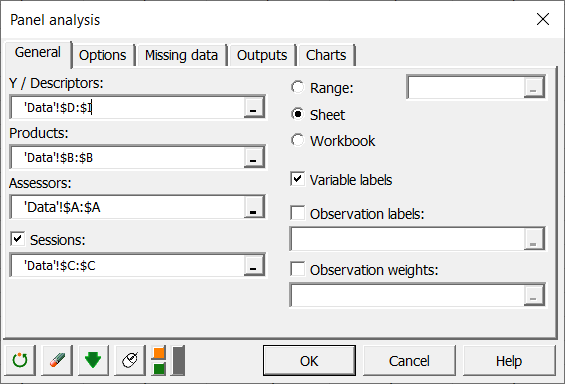
Markieren Sie die Daten in dem Excel-Tabellenblatt. Da hier ein Sitzungsfaktor zur Verfügung steht, aktivieren wir die Option und wählen die entsprechende Spalte.
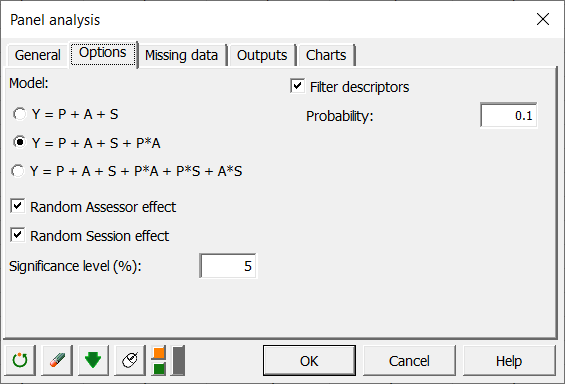
Es stehen mehrere Modelle zur Verfügung, je nachdem, ob Sie eine Sitzung auswählen, ob Sie ein Modell mit oder ohne Interaktionen zwischen den Faktoren wünschen und ob Sie davon ausgehen, dass der Bewerter und die Sitzung (Wiederholung) zufällig oder fixe Effekte sind. Zufällige Faktoren werden als Zufallsvariablen mit Mittelwert 0 und einer gegebenen Varianz betrachtet. Das bedeutet, dass Sie davon ausgehen, dass nach Berücksichtigung der Produktwirkung die anderen Effekte rein auf die Randomisierung zurückzuführen sind. Dies ist nur gültig, wenn Sie davon ausgehen können, dass keine strukturelle Differenz zwischen den Bewertern oder zwischen Sitzungen besteht. Diese Annahmen können in der folgenden Analyse überprüft werden.
Interpretieren der Ergebnisse einer sensoriellen Panelanalyse
Nachdem Sie auf den Button OK geklickt haben, beginnen die Berechnungen. Da viele Diagramme erstellt werden, kann es etwas dauern bis Sie sich im Ergebnis-Tabellenblatt bewegen können. Wir empfehlen, nicht in Excel zu klicken bis der Pfeil-Cursor wieder erscheint.
Die erste Tabelle entspricht grundsätzlichen zusammenfassenden Statistiken für die verschiedenen Eingangsvariablen. Sie können die Informationen zum Minimum und Maximum verwenden, um sicherzustellen, dass keine absurden Werte für die Deskriptoren vorhanden sind.
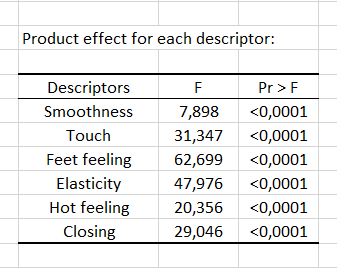
Der erste Schritt der Analyse besteht in der Durchführung einer ANOVA auf dem gesamten Datensatz für jeden Deskriptor nacheinander, um die Deskriptoren zu identifizieren, für die keine Produktwirkung eintritt. Für jeden Deskriptor wird die Tabelle vom Typ III SS der ANOVA für das ausgewählte Modell angezeigt. Wenn für einen Deskriptor kein Produkteffekt eintritt, d. h. wenn der p-Wert höher ist als ein gegebener Schwellwert, kann dieser Deskriptor aus der Analyse entfernt werden, solange die entsprechende Option in der Registerkarte Optionen des Dialogfensters markiert wurde. Die nachstehende Tabelle entspricht der Tabelle für die Glätte.

Dann ermöglicht eine zusammenfassende Tabelle den Vergleich der p-Werte der Produktwirkung für die verschiedenen Deskriptoren. Die Analysen, die folgen, werden nur für die Deskriptoren durchgeführt, die eine Unterscheidung der Produkte ermöglichen, d. h. für alle Deskriptoren, für die der p-Wert kleiner als 0,05 ist, da wir diesen Schwellwert im Dialogfenster eingegeben haben. In unserem besonderen Fall gibt es eine Produktwirkung für alle Deskriptoren, somit bleiben alle Deskriptoren in den nächsten Schritten erhalten.
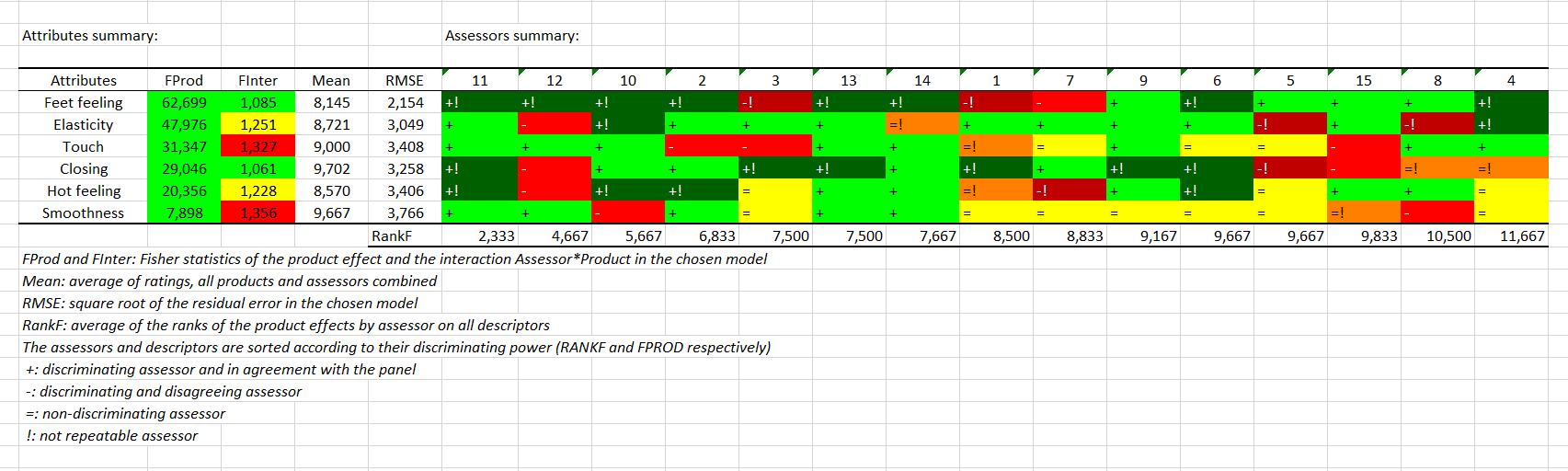
Dann kommt die Tabelle CAP (Kontrolle der Leistung der Prüfer). Beachten Sie, dass diese Ausgabe auf ANOVA-Berechnungen basiert und daher nur erzeugt wird, wenn jedes Produkt mindestens 2 Mal gesehen wurde, oder anders gesagt, wenn die Anzahl der Beobachtungen größer ist als die Anzahl der Richter multipliziert mit der Anzahl der Produkte. Der linke Teil ist eine Zusammenfassung der Deskriptoren. Sie sind nach ihrer Produktdiskriminierung sortiert. Wenn der p-Wert kleiner als 0,1 ist, ist die Farbe gelb. Ist der p-Wert kleiner als 0,05, ist die Farbe grün. Andernfalls ist die Farbe rot. Bei der Interaktion zwischen Produkt*Bewerter ist es genau umgekehrt, da es nicht positiv ist, eine signifikante Interaktion zu haben. Der Durchschnitt des Attributs und die Quadratwurzel des Fehlers sind in den Spalten 3 und 4 verfügbar.
Die rechte Seite der Tabelle bezieht sich auf Assessoren. Achtung, wenn ein Filter angewendet wurde, wird dieser Teil unter dem vorhergehenden angezeigt. Die Assessoren sind nach ihrem durchschnittlichen Rang-Mittelwert der individuell erzeugten Effekte auf alle Deskriptoren sortiert. Wenn ein Assessor für einen bestimmten Deskriptor die Produkte nicht diskriminiert, erhält er oder sie ein "=". Wenn er/sie die Produkte diskriminiert und mit dem Panel übereinstimmt (Test auf seinen Beitrag zur Interaktion zwischen Thema*Produkt), erhält er/sie ein "+". Andernfalls wird ein "-" angezeigt. Wenn der Assessor schließlich einen Sitzungseffekt für den entsprechenden Deskriptor hat (Stimmungseffektg), oder wenn er/sie von einer Sitzung zur nächsten deutlich weniger zuverlässig ist als andere Juroren, wird er/sie als nicht wiederholbar betrachtet und erhält dann ein "!
Der zweite Schritt besteht aus einer grafischen Analyse. Für die 6 Deskriptoren werden Boxplots und Stripplots angezeigt. Wir können so sehen, wie unterschiedliche Bewerter die Bewertungsskala für jeden Deskriptor verwenden, um die verschiedenen Produkte zu bewerten. Auf dem Boxplot für Glätte können wir sehen, dass die Bewerter 9 und 15 trotz eines ähnlichen Mittelwerts die Bewertungsskala unterschiedlich verwenden. Wir sehen auch, dass die Bewerter 3,4,5,6 und 7 trotz der Verwendung von ähnlichen Bewertungsbereichen dazu neigen, hinsichtlich der Position unterschiedliche Bewertungen zu vergeben. Natürlich sagen solche Diagramme nichts über die Übereinstimmung zwischen den Bewertern aus: Sie könnten einem Fall begegnen, bei dem trotz der sehr ähnlichen Boxplots das Produkt, das dem Minimum für einen Bewerter entspricht (Minimum- und Maximumwerte werden mit blauen Punkten auf den Boxplots dargestellt), bei einem anderen Bewerter dem Maximum entspricht.

Wir wollen jetzt überprüfen, ob die Bewerter für die verschiedenen Deskriptoren übereinstimmen, und wie die Deskriptoren verschiedene Bewertungsmöglichkeiten liefern (sind sie korreliert oder nicht). Der dritte Schritt beginnt mit der Umstrukturierung der Datentabelle, um eine Tabelle zu erhalten, die eine Zeile pro Produkt und eine Spalte pro Paar aus Bewerter und Deskriptor enthält - falls mehrere Sitzungen vorhanden sind, enthält die Tabelle Mittelwerte - gefolgt von einer HKA auf dieser Tabelle. Die HKA wird auf standardisierten Daten durchgeführt.
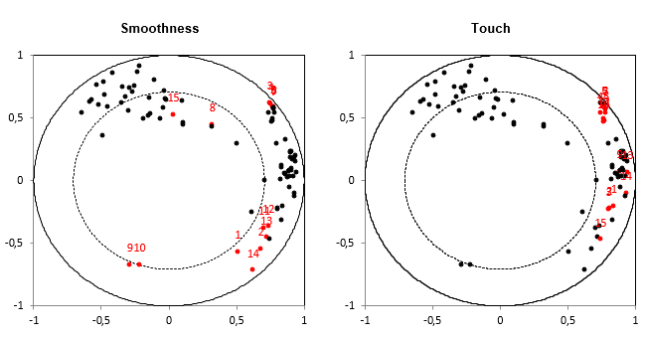
Das nachstehend abgebildete Diagramm entspricht demselben HKA-Korrelationsdiagramm, der für jeden Deskriptor repliziert wird und in dem die Punkte der 15 Paare (Bewerter, Deskriptor) entsprechend dem im Titel genannten Deskriptor Rot markiert sind. Dies ermöglicht die Untersuchung des Ausmaßes, in dem Bewerter für alle Deskriptoren übereinstimmen oder nicht, in einem Schritt nachdem die Positions- und Skaleneffekte entfernt wurden (da die HKA für standardisierte Daten durchgeführt wird).
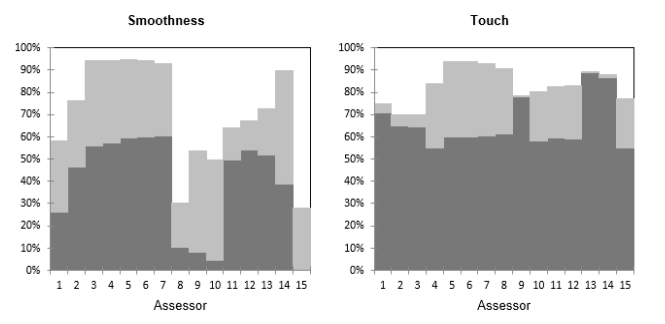
Das folgende Diagramm gibt für jedes Paar (Bewerter, Deskriptor) den Prozentsatz der Varianz an, der auf dem HKA-Diagramm aufgetragen ist. In dunkelgrau können Sie den Prozentsatz sehen, der auf der ersten Achse aufgetragen ist, und in hellgrau den Prozentsatz der Varianz, der auf der zweiten Achse aufgetragen ist. Wir sehen, dass es für Glätte verschiedene Gruppen von Bewertern gibt, wobei die Bewerter (8,9,10) sich mehr auf die zweite Achse beziehen, aber immer noch schlecht repräsentiert sind. Wir können auch bestätigen, dass Elastizität und Schließen nahe beieinander liegen und auf der zweiten Achse aufgetragen sind.
Um die Beziehung zwischen Deskriptoren genauer zu untersuchen, wird ein MFA-Diagramm (Multiple Faktorenanalyse) der Deskriptoren angezeigt. Die MFA basiert auf einer Tabelle, in der genauso viele Untertabellen wie Deskriptoren vorhanden sind, wobei jede Untertabelle die Durchschnitte für jedes Produkt (Zeilen) von jedem Bewerter (Spalten) enthält.

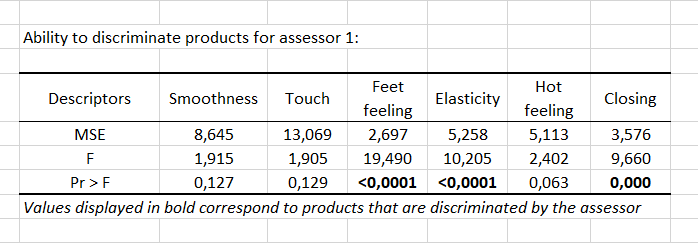
Während des vierten Schrittes wird eine ANOVA für jeden Bewerter und für jeden der 6 Deskriptoren separat durchgeführt, um zu überprüfen, ob es eine Produktwirkung gibt oder nicht, um für jeden Bewerter zu bestätigen, ob er/sie dazu in der Lage ist, die Produkte mithilfe der verfügbaren Deskriptoren zu unterscheiden. Eine Tabelle wird für jeden Bewerter angezeigt, um zu zeigen, ob eine Produktwirkung für die verschiedenen Deskriptoren vorliegt oder nicht. Die p-Werte werden fettgedruckt angezeigt, wenn sie kleiner sind als der Schwellwert, der in der Registerkarte Optionen des Dialogfensters definiert ist. Die fett dargestellten p-Werte entsprechen den Deskriptoren, für die der Bewerter die Produkte differenzieren konnte. Die nachstehende Tabelle entspricht dieser Tabelle für Bewerter 1. Wir können sehen, dass dieser Bewerter imstande war, die Produkte anhand des Fußgefühls und Elastizität zu differenzieren.
Eine zusammenfassende Tabelle wird dann dazu verwendet, für jeden Bewerter die Anzahl von Deskriptoren zu ermitteln, für die er die Produkte differenzieren konnte. Der entsprechende Prozentsatz wird angezeigt. Dieser Prozentsatz ist ein einfaches Maß für das Unterscheidungsvermögen der Bewerter. Die Prozentsätze werden dann in einem Säulendiagramm angezeigt.

Für den fünften Schritt zeigt eine globale Tabelle anfänglich Bewertungen (als Durchschnittswerte der Sitzungen, falls zutreffend) für jeden Bewerter in Zeilen und jedes Paar (Produkt, Bewerter) in Spalten. Darauf folgt eine Reihe von Tabellen und Diagrammen, um die Bewerter (als Durchschnittswerte möglicher Wiederholungen) Produkt für Produkt für die Gruppe von Deskriptoren zu vergleichen. Diese Diagramme können zur Identifizierung starker Trends und möglicher atypischer Bewertungen für bestimmte Bewerter verwendet werden. Die rote Linie entspricht dem Mittelwert für alle Bewerter für das Produkt von Interesse und die blaue Linie dem in der Liste oben links in dem Diagramm ausgewählten Bewerter. Im nachstehenden Beispiel können wir sehen, dass der Bewerter 10 das Produkt 7 unterdurchschnittlich für Glätte und Oberfläche bewertete, während die anderen Deskriptoren durchschnittlich bewertet wurden.

Der sechste Schritt ermöglicht die Identifizierung atypischer Bewerter durch Messung des euklidischen Abstands jedes Bewerters für jedes Produkt bis zu einem Mittelwert für alle Bewerter im Bereich aller Deskriptoren. Eine Tabelle, in der diese Abstände für jedes Produkt sowie das Minimum und Maximum, das für alle Bewerter berechnet wurde, dargestellt sind, ermöglicht die Identifizierung der Bewerter, die nahe an der Übereinstimmung liegen oder weit davon entfernt sind. Das folgende Diagramm ermöglicht die Visualisierung dieser Abstände. Je geringer der Abstand, desto näher liegt der Bewerter an der Übereinstimmung (dem Zentroid). Wert 0 entspricht dem Mittelwerte für alle Bewerter. Wenn alle Bewerter für ein bestimmtes Produkt die gleiche Bewertung für alle Deskriptoren abgeben würden, wäre der Min und Max für dieses Produkt 0. Wenn ein Bewerter genau den Wert angeben würde, der dem über die anderen Deskriptoren erhaltenen Mittelwert entspricht, hätten wir das Ergebnis, dass das Minimum gleich null für dieses Produkt ist. Im nachstehenden Beispiel sehen wir, dass Bewerter 4 nicht mit den anderen Bewertern übereinstimmt, außer für Produkt 10, bei dem seine Bewertung näher am Mittelwert liegt.

Da eine Sitzungsvariable ausgewählt wurde, wir beim siebten Schritt überprüft, ob für bestimmte Bewerter ein Session-Effekt, normalerweise eine Ordnungswirkung, eintritt. Diese wird mithilfe eines Wilcoxon-Vorzeichen-Rang-Tests bewertet, da nur zwei Sitzungen vorhanden sind (im Fall von 3 oder mehreren Sitzungen wird ein Friedman-Test eingesetzt). Der Test wird für alle Produkte Deskriptor für Deskriptor berechnet. In der nachstehenden Tabelle können wir sehen, dass für 4 von 6 Deskriptoren ein Session-Effekt für Bewerter 1 basierend auf dem nichtparametrischen Test eintritt. Wir können ebenfalls sehen, dass für das Fußgefühl ein Session-Effekt für 9 von 15 Bewertern eintritt.
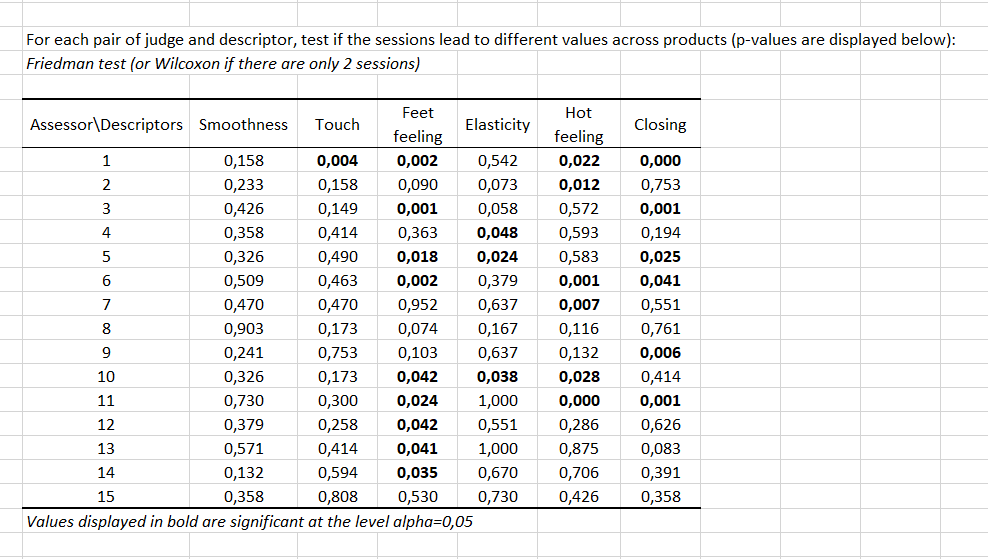
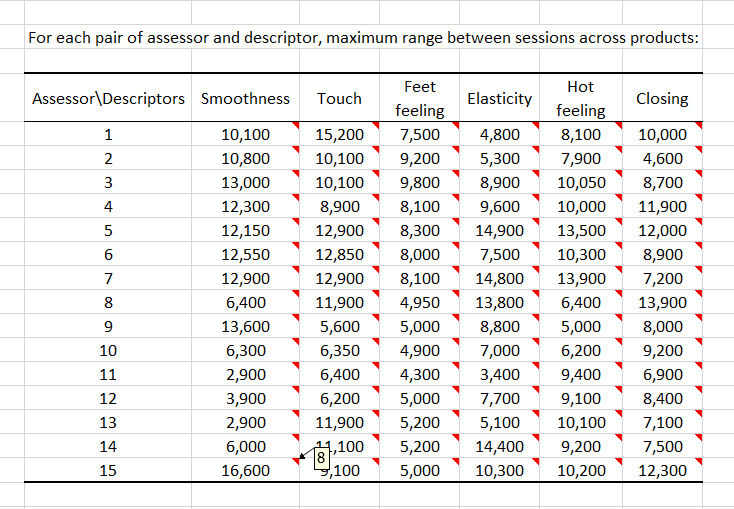
Dann berechnen wir für jeden Bewerter und jeden Deskriptor, welches der maximale beobachtete Bereich zwischen Sitzungen für alle Produkten ist. Sie können das Produkt sehen, das dem maximalen Bereich entspricht, indem Sie mit der Maus auf das rote Dreieck zeigen, das in jeder Zelle angezeigt wird. Wir sehen beispielsweise, dass es einen hohen Bereich für Bewerter 15 zu Glätte gibt, und dass er Produkt 8 entspricht. In unserem besonderen Fall sehen wir hier, dass für die meisten Paare (Bewerter, Deskriptor) hohe Bereiche vorhanden sind. Dadurch wird die Gültigkeit dieser Umfrage in Frage gestellt.
Da für jede Dreiergruppe (Bewerter, Produkt, Deskriptor) mindestens eine Bewertung existiert, besteht der achte Schritt aus einer Klassifikation der Bewerter. Die Klassifikation wird zuerst an den Rohdaten und danach an den standardisierten Daten durchgeführt, um mögliche Skalen- und Positionseffekte zu vermeiden.
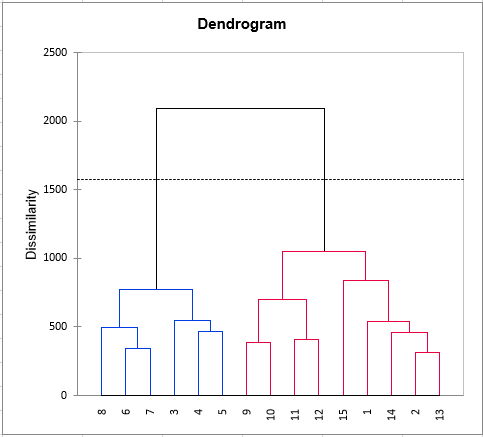
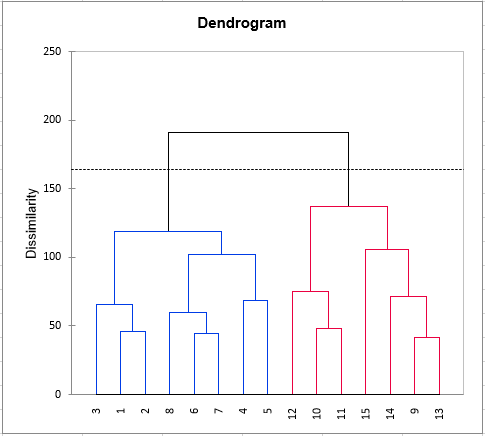
Schließlich wird eine für eine generalisierte Procrustes Analyse (GPA) vorformatierte Tabelle angezeigt, falls Sie eine GPA durchführen möchten.
War dieser Artikel nützlich?
- Ja
- Nein