Statis Analyse in Excel
Dieses Tutorial zeigt Ihnen, wie Sie eine STATIS-Analyse in Excel mit der Statistiksoftware XLSTAT ausführen und interpretieren.
Datensatz für STATIS
Die Daten stammen aus einer von AGROCAMPUS OUEST in Rennes durchgeführten projektiven Mapping / Napping-Studie. 8 Smoothies wurden von 24 Probanden (Probanden) verkostet und dann auf eine Tischdecke gelegt. Die Koordinaten wurden für die STATIS-Analyse gesammelt. Wenn ein Diskussionsteilnehmer zwei Produkte als ähnlich betrachtet, werden sie auf der Tischdecke nah beieinander gelegt, so dass sie ähnliche Koordinaten haben. Die Originaldatei kann mit dem R SensoMineR-Paket abgerufen werden.
Ziel der Anleitung
Das Ziel dieses Tutorials ist es, die Verbindungen zwischen Smoothies zu studieren und zu visualisieren sowie die Gemeinsamkeiten zwischen den Probanden zu bestimmen.
Was ist die STATIS Methode?
The STATIS method is a multi-configuration data analysis commonly used in sensory analysis. The configurations represent the various assessors, subjects or judges. This method can be particularly used in the case of projective mapping / Napping, conventional profiling or free choice profiling. The great interest of STATIS is that atypical configurations have a smaller weight than the weigh of central configurations. The analysis, therefore, best reflects the general point of view and not those atypical configurations.
Einrichten einer STATIS-Analyse mit XLSTAT
Um das Dialogfeld STATIS zu aktivieren, starten Sie XLSTAT und wählen Sie Erweiterte Funktionen / Analyse der sensorischen Daten / STATIS aus.
 Das Dialogfeld STATIS wird angezeigt.
Das Dialogfeld STATIS wird angezeigt.
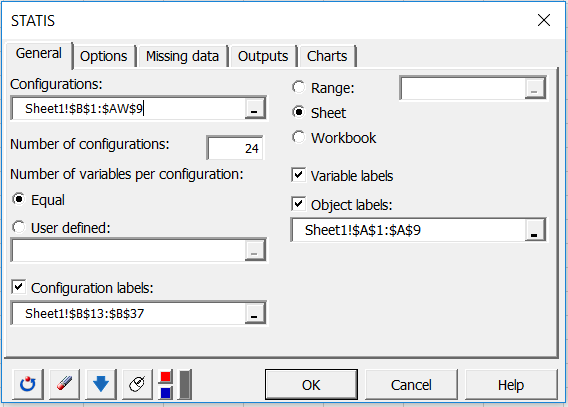
Wählen Sie die Daten aus, die den Konfigurationen entsprechen (eine Konfiguration entspricht hier dem von einem Betreff angegebenen Koordinatensatz).
Die Anzahl der Konfigurationen muss eingegeben werden. Hier geben wir 24 Subjekte ein.
Da jede Konfiguration über zwei Variablen verfügt, können Sie XLSTAT mitteilen, dass die Anzahl der Variablen konstant ist, indem Sie die Option Gleich wählen. Wenn die Anzahl der Variablen für mindestens eine Konfiguration unterschiedlich ist, müssen Sie eine Spalte auswählen, die die Anzahl der Variablen für jede Konfiguration enthält.
Aktivieren Sie abschließend die Optionen Variablenbeschriftungen und Objektbeschriftungen (in unserem Fall die Smoothies).
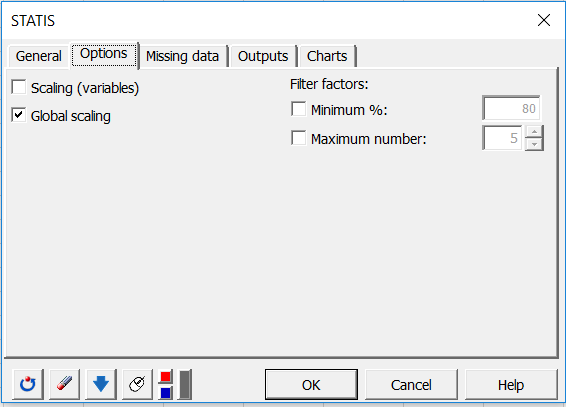
In der Registerkarte Optionen haben wir uns entschieden, die Konfigurationen global zu reduzieren, um den Skaleneffekt zu vermeiden. Da sich alle Variablen in jeder Konfiguration auf derselben Skala befinden, ist es nicht notwendig, die Variablen zu reduzieren.
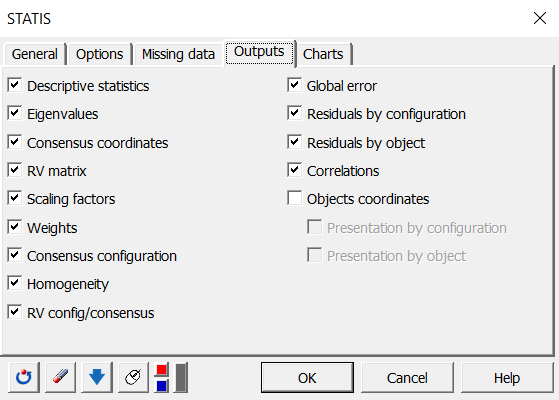
In der Registerkarte Ergebnisse haben wir uns entschieden, die RV-Matrix sowie die RV unter den Konfigurationen und den Konsens anzuzeigen, um Indikatoren für die Nähe zwischen den Subjekten zu haben.
Die Berechnungen beginnen, sobald Sie auf OK geklickt haben.
Bestätigen Sie die Achsen, für die Sie Diagramme anzeigen möchten. In diesem Beispiel ist der von den ersten beiden Faktoren dargestellte Prozentsatz der Variabilität nicht sehr hoch (68,43%); Um eine Fehlinterpretation der Ergebnisse zu vermeiden, haben wir uns entschlossen, die Ergebnisse mit einem zweiten Diagramm auf den Achsen 1 und 3 zu ergänzen.
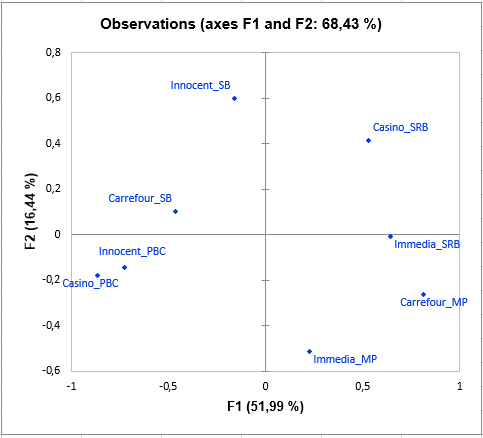
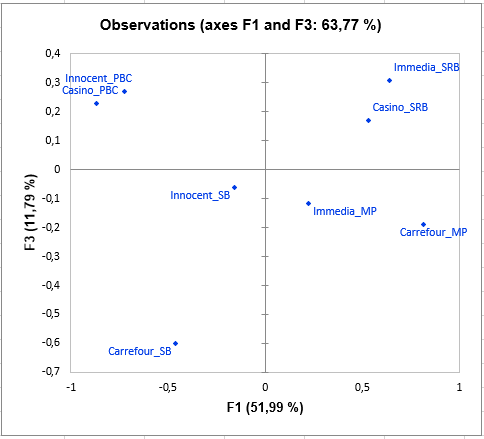
Interpretation der Ergebnisse einer STATIS-Analyse
Die folgende Grafik ist das Hauptziel von STATIS: Die Beobachtungen auf einer 2-dimensionalen Karte darzustellen und damit die Nähe zu identifizieren. Zum Beispiel sehen wir, dass "Casino_PBC" und "Innocent_PBC" Smoothies als nah wahrgenommen werden, sich aber sehr von "Casino_SRB" unterscheiden. In der dritten Dimension sehen wir, dass Carrefour_SB "Casino_PBC", "Innocent_PBC", "Immedia_SRB" und "Casino_SRB" völlig ablehnt.
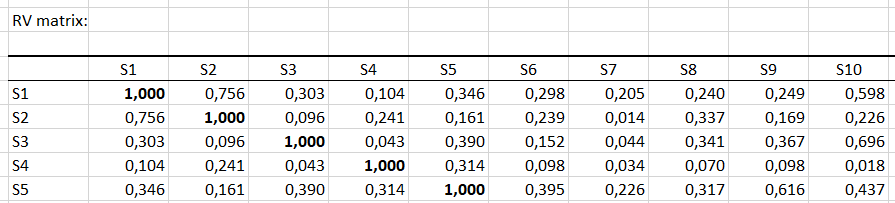
 Wenn wir uns für zwei bestimmte Subjekte interessieren (Panelteilnehmer), ist es nützlich, die RV-Matrix zu betrachten, die den Koeffizienten RV für jedes Subjekt ergibt (dieser Koeffizient liegt zwischen 0 und 1 und steigt mit der Nähe der Subjekte an). Wir sehen hier, dass Subjekt 1 eine sehr ähnliche Meinung zu Subjekt 2 hat, aber sehr verschieden von Subjekt 4 (das bei vielen anderen Subjekten niedrige RV-Werte aufweist).
Wenn wir uns für zwei bestimmte Subjekte interessieren (Panelteilnehmer), ist es nützlich, die RV-Matrix zu betrachten, die den Koeffizienten RV für jedes Subjekt ergibt (dieser Koeffizient liegt zwischen 0 und 1 und steigt mit der Nähe der Subjekte an). Wir sehen hier, dass Subjekt 1 eine sehr ähnliche Meinung zu Subjekt 2 hat, aber sehr verschieden von Subjekt 4 (das bei vielen anderen Subjekten niedrige RV-Werte aufweist).
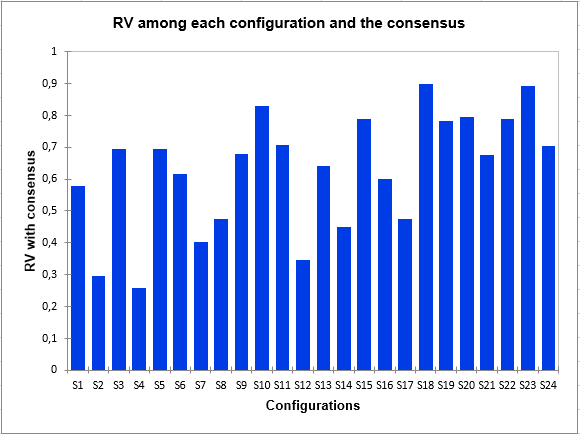
 Es kann sehr wichtig sein, die Nähe eines Subjekts zu allen anderen zu beurteilen, d. H. Die Gesamtperspektive, die der Konsens widerspiegelt. Das folgende Balkendiagramm zeigt also, dass das Subjekt 4 im Gegensatz zu 18 oder 23 ein eher untypisches Subjekt ist.
Es kann sehr wichtig sein, die Nähe eines Subjekts zu allen anderen zu beurteilen, d. H. Die Gesamtperspektive, die der Konsens widerspiegelt. Das folgende Balkendiagramm zeigt also, dass das Subjekt 4 im Gegensatz zu 18 oder 23 ein eher untypisches Subjekt ist.
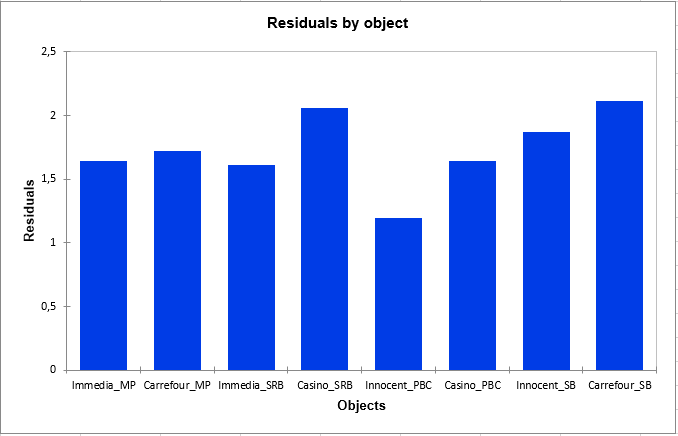
 Schließlich zeigt die folgende Grafik die Residuen nach Objekt, die angeben, welche Objekte von den Probanden auf die gleiche Weise platziert wurden, wie der Smoothie "Innocent_PBC", oder anders ausgedrückt, wie der Smoothie "Carrefour_SB".
Schließlich zeigt die folgende Grafik die Residuen nach Objekt, die angeben, welche Objekte von den Probanden auf die gleiche Weise platziert wurden, wie der Smoothie "Innocent_PBC", oder anders ausgedrückt, wie der Smoothie "Carrefour_SB".
War dieser Artikel nützlich?
- Ja
- Nein