Analyse de la qualité d'un panel sensoriel dans Excel
Ce tutoriel explique comment calculer et interpréter une analyse de panel avec Excel en utilisant XLSTAT.
Jeu de données pour réaliser l'analyse de panel
Les données utilisées dans ce tutoriel correspondent à l'évaluation de 14 chaussures de ski différentes par 15 skieurs (dénommés par la suite « sujets ») ayant une expérience dans les tests sensoriels pour l'industrie du vêtement. 6 descripteurs ont été utilisés par les 15 sujets pour évaluer les chaussures.
But de ce tutoriel
Le but ici est d’étudier en profondeur les résultats donnés par le panel dont notamment : - Les performances de discrimination de chaque sujet.
-
Les performances de répétabilité de chaque sujet.
-
Les accords entre les sujets
Dans cet objectif, nous utiliserons la fonction Analyse de Panel de XLSTAT. Le paramétrage sera suivi de l’interprétation des sorties.
Paramétrer la boîte de dialogue de l’Analyse de Panel
Une fois XLSTAT lancé, sélectionnez le menu XLSTAT / Fonctions avancées / Analyse de données sensorielles/ Analyse de Panel.

La boîte de dialogue Analyse de Panel apparaît.
Dans l’onglet Général, vous pouvez alors sélectionner les descripteurs, les produits et les sujets.
Si vous avez plusieurs Sessions, vous pouvez également les sélectionner.
Dans l’onglet Options, plusieurs modèles sont possibles selon que vous sélectionnez une session, que vous voulez un modèle avec ou sans interactions entre les facteurs, ou que vous considérez que les facteurs sujet et session (répétition) sont des facteurs aléatoires ou fixes. Les facteurs aléatoires sont considérés comme des variables aléatoires de moyenne 0 et de variance à déterminer. Cela signifie que vous considérez que, une fois l'effet produit pris en compte, les effets des autres facteurs sont uniquement liés au « hasard ». Ceci n'est valable que si vous pouvez considérer qu'il n’y a aucune différence structurelle entre les sujets ou entre les sessions. Ces hypothèses peuvent être testées grâce aux analyses qui suivent.
Interpréter les résultats d’une Analyse de Panel
Une fois que vous avez cliqué sur le bouton OK les calculs commencent. Comme de nombreux graphiques sont créés, il peut se passer plusieurs minutes avant que vous puissiez naviguer dans la feuille des résultats. Nous vous recommandons de ne pas cliquer dans Excel jusqu'à ce que la flèche du curseur de la souris soit à nouveau affichée.
Le premier tableau correspond à des statistiques basiques pour les différentes variables d'entrée. Vous pouvez utiliser l'information sur le minimum et le maximum pour vous assurer qu'il n'y a pas de valeurs absurdes pour les descripteurs.
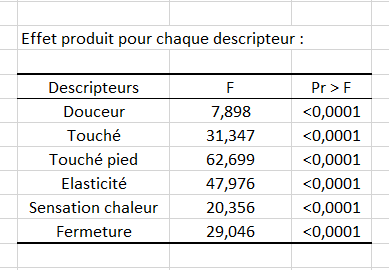
La première étape consiste en une série d’ANOVA dont le but est de vérifier pour chaque descripteur s’il permet de mettre en évidence un effet produit ou non. Pour chaque descripteur, le tableau des sommes des carrés de Type III de l’ANOVA pour le modèle choisi est affiché. S‘il n'y a aucun effet produit pour un descripteur, autrement dit que la p-value est supérieure au seuil indiqué dans Options, ce descripteur peut être retiré pour la suite de l'analyse si l’option correspondante a été cochée dans l'onglet Options de la boîte de dialogue. Le tableau ci-dessous correspond au tableau obtenu pour la Douceur. 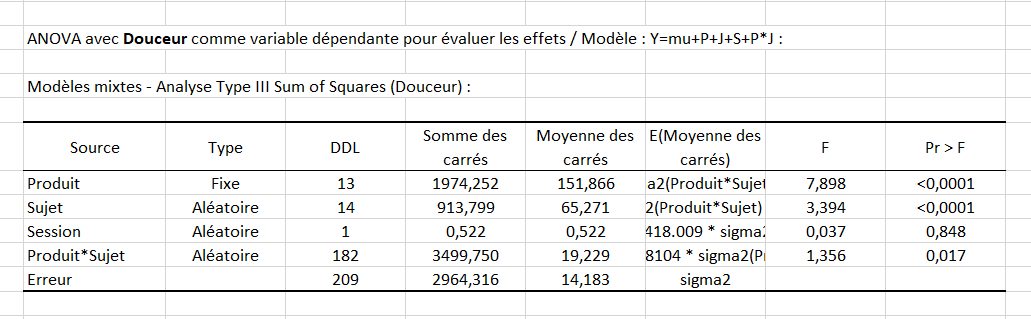 Ensuite, un tableau de synthèse permet de comparer les p-values associées au facteur produit pour les différents descripteurs. La suite de l’analyse ne sera conduite que pour les descripteurs permettant de différencier les produits ce qui dans notre cas veut dire pour les descripteurs pour lesquels la p-value est inférieure à 0.1, valeur seuil que nous avons entré dans la boîte de dialogue. Ici, tous les descripteurs sont retenus.
Ensuite, un tableau de synthèse permet de comparer les p-values associées au facteur produit pour les différents descripteurs. La suite de l’analyse ne sera conduite que pour les descripteurs permettant de différencier les produits ce qui dans notre cas veut dire pour les descripteurs pour lesquels la p-value est inférieure à 0.1, valeur seuil que nous avons entré dans la boîte de dialogue. Ici, tous les descripteurs sont retenus.
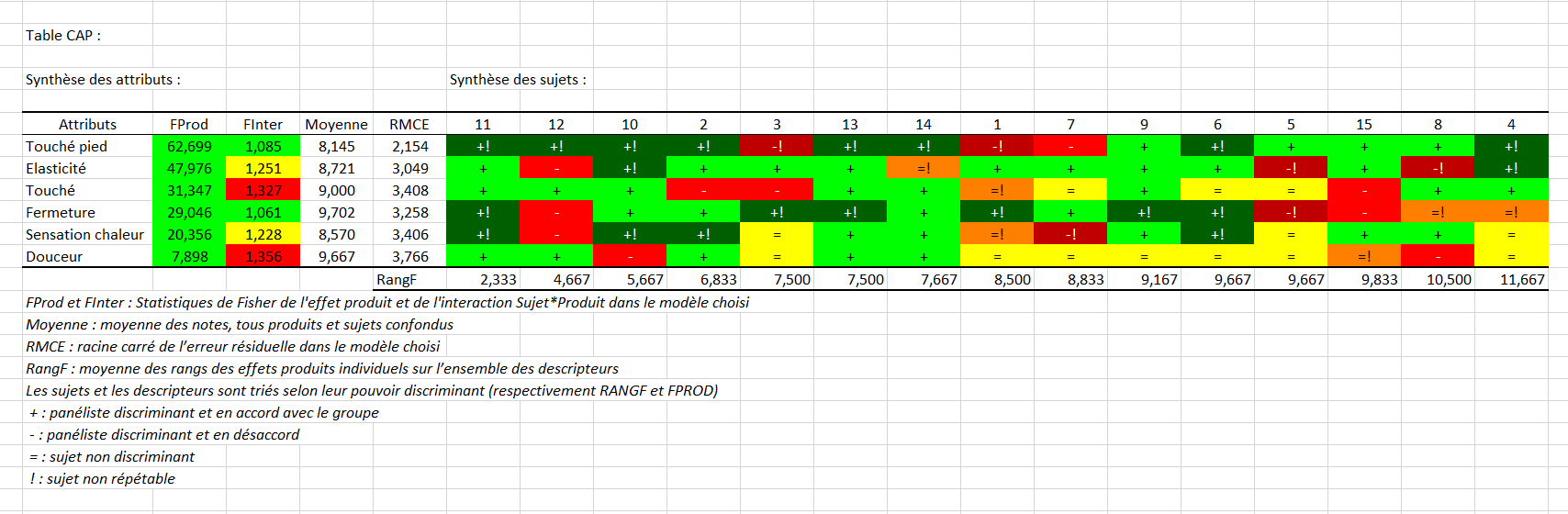
Vient ensuite la table CAP (Control of Assessor Performances). À noter que cette sortie repose sur des calculs d'ANOVA et n'est par conséquent générée que si chaque produit a été vu au moins 2 fois, ou autrement dit que le nombre d'observations soit supérieur au produit du nombre de juges et du nombre de produits. La partie gauche est un résumé des descripteurs. Ces derniers sont triés en fonction de leur discrimination des produits. Si la p-value est inférieure à 0.1, la couleur sera jaune. Si elle est inférieure à 0.05, la couleur sera verte. Autrement, la couleur sera rouge. C’est exactement le contraire pour l’interaction produit*sujet puisque ce n’est pas une chose positive d’avoir une interaction significative. La moyenne de l’attribut et la racine carrée de l’erreur terminent cette partie gauche.
La partie droite du tableau concerne les sujets. Attention, si un filtrage a été effectué, cette partie sera affichée sous la précédente. Les sujets sont triés en fonction de leur moyenne des rangs des effets produits individuels sur l’ensemble des descripteurs. Pour un descripteur donné, si un sujet ne discrimine pas les produits, il aura alors un « = ». S’il les discrimine, soit il est en accord avec le panel (test sur sa contribution à l’interaction sujet*produit) et aura un « + », sinon il aura un « - ». Enfin, si le sujet a un effet session pour le descripteur en question (effet d'humeur), ou s’il est significativement moins fiable que les autres sujets d'une session à l'autre, il est considéré non répétable et aura alors un « ! » ajouté.
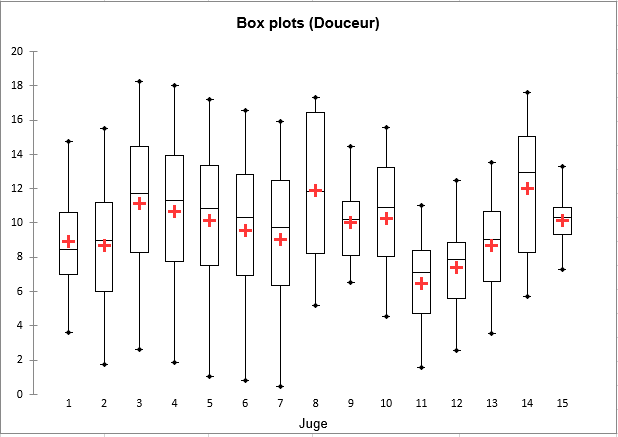
La seconde étape consiste en une analyse graphique. Pour chacun des 6 descripteurs sont affichés des box plots et des strip plots. On peut ainsi visualiser comment, pour chaque descripteur, les différents sujets utilisent l’échelle de notation pour évaluer les différents produits.
Sur le box plot pour la Douceur, nous pouvons voir que les sujets 9 et 15, tout en ayant une moyenne similaire, utilisent l'échelle de notation de manière différente. Nous pouvons également voir que les sujets 3, 4, 5, 6 et 7, tout en utilisant des amplitudes de notation similaires ont tendance à noter de manière différente en termes de moyenne. Bien sûr, ces graphiques n’indiquent rien quant à un accord entre les sujets : on peut imaginer un cas où, tandis que les box plots sont très semblables, le produit correspondant au minimum pour un sujet (les valeurs minimales et maximales sont affichées avec des points bleus sur les box plots) pourrait correspondre au maximum pour un autre sujet.
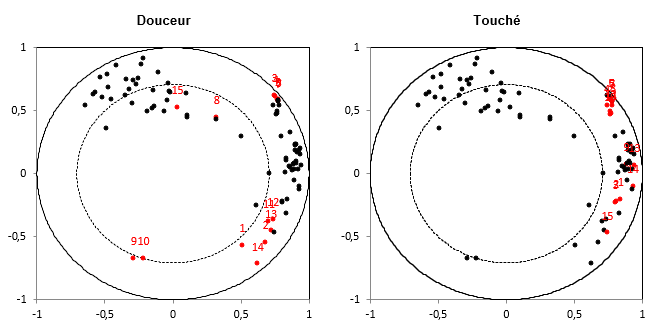
Nous voulons maintenant vérifier si les sujets sont d'accord pour les différents descripteurs, et comment les descripteurs permettent des possibilités d’évaluation différentes (sont-ils corrélés ou non ?).
La troisième étape consiste en une restructuration du tableau de données, afin d’avoir un tableau contenant une ligne par produit et une colonne par couple de sujet et descripteur (s’il y a des sessions, le tableau contient alors les moyennes), puis en une ACP (normée) sur ce tableau.
Le graphique correspond à un même graphique (cercle des corrélations) issu de l’ACP répliqué pour chaque descripteur, en mettant en évidence en rouge les 15 paires (sujet, descripteur) correspondant au descripteur mentionné dans le titre. On peut ainsi vérifier en une étape dans quelle mesure les sujets sont d’accord ou non pour les descripteurs, une fois l’effet de position et d’échelle supprimé (car l’ACP est normée), et dans quelle mesure les descripteurs sont liés ou non.
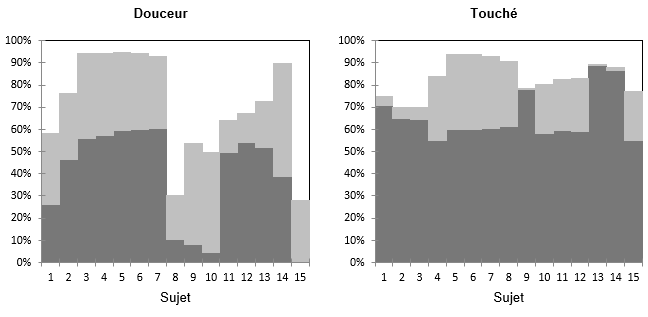
Le graphique qui suit indique le % de la variance pour chaque couple (sujet, descripteur) représenté sur le graphique précédent, avec en gris foncé le % sur le premier axe et en gris clair le % sur le second axe. Nous voyons que pour la Douceur, il y a différents groupes de sujets, avec les sujets 8, 9 et 10)qui sont davantage liés au deuxième axe mais assez mal représentés.
Afin d’étudier plus précisément la relation entre les descripteurs, une AFM (Analyse Factorielle Multiple) est réalisée, sur un tableau dans lequel on a autant de sous-tableaux qu’il y a de descripteurs. Chaque sous-tableau contient les données moyennes observées pour chaque produit (en ligne) par chaque sujet (en colonne).
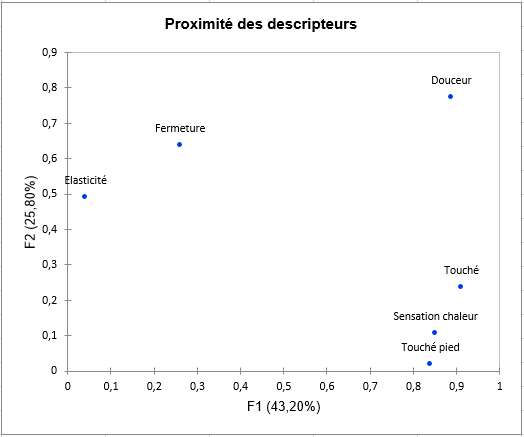
Au cours de la quatrième étape est réalisée pour chaque sujet, une ANOVA pour chacun des 6 descripteurs afin de vérifier s’il y a un effet produit. Cela permet d’évaluer pour chaque sujet sa capacité à distinguer les produits au travers des critères/descripteurs utilisés. Ceci permet de voir si le tableau de la première étape était très dépendant de notre valeur de niveau de signification donné dans Options.
Le tableau ci-dessous correspond aux résultats pour le sujet 1. Les p-values affichées en gras correspondent à des descripteurs pour lesquels l'évaluateur a pu différencier les produits. Nous pouvons voir que ce sujet a pu différencier les produits en utilisant Touché pied, Elasticité et Fermeture.
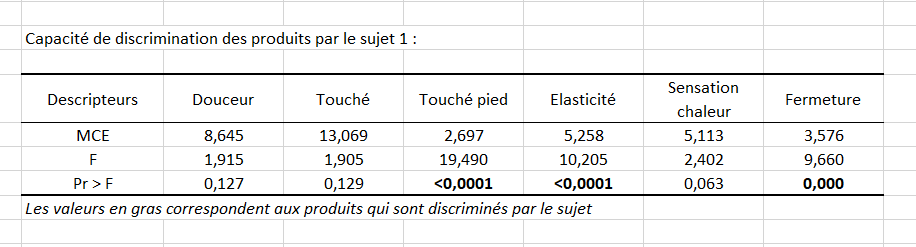
Un tableau de synthèse permet ensuite de compter pour chaque sujet le nombre de descripteurs pour lesquels il a pu faire la différence entre les produits et le pourcentage correspondant est affiché. Ce pourcentage est une mesure simple du pouvoir discriminant des sujets. Les pourcentages sont ensuite affichés sur un diagramme en bâtons.
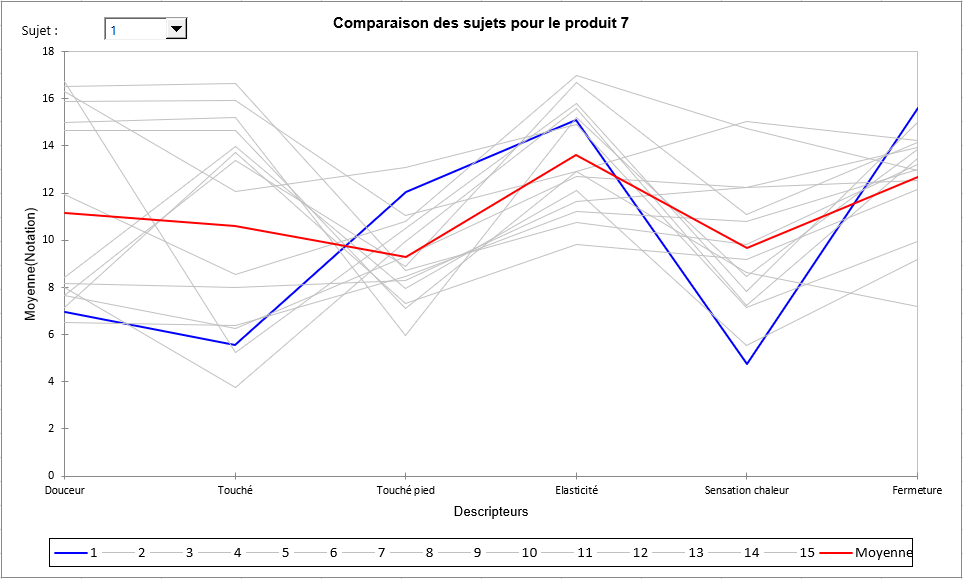
Pour la cinquième étape, un tableau global présente dans un premier temps les notes (moyennées sur les sessions éventuelles) pour chaque sujet en ligne et chaque couple (produit, descripteur) en colonne. Il est suivi d’une série de tableaux et graphiques permettant, pour chaque produit pris séparément, de comparer les sujets (moyennés sur les sessions éventuelles) pour l’ensemble des descripteurs. Ces graphiques permettent d’identifier des tendances fortes et d’éventuelles notations atypiques pour certains sujets. La ligne rouge correspond à la valeur moyenne sur tous les sujets pour le produit en question et, la ligne bleue, au sujet sélectionné dans la liste en haut à gauche du graphique. Dans l'exemple ci-dessous nous pouvons voir que le sujet 1 a noté le produit 7 au-dessous de la moyenne pour la Douceur, le Touché et la Sensation chaleur ; et proche de la moyenne pour les autres descripteurs.
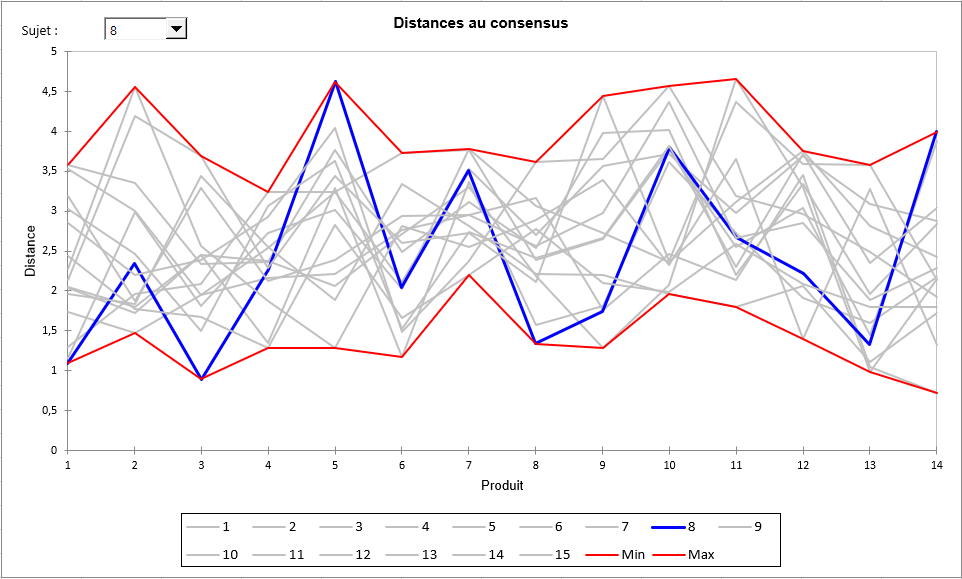
La sixième étape permet de repérer les sujets atypiques au travers de la mesure pour chaque produit d’une distance euclidienne de chaque sujet à une moyenne calculée sur l’ensemble des sujets dans l’espace des descripteurs. Un tableau affichant ces distances ainsi que pour chaque produit le minimum et le maximum, permet d’identifier les sujets proches ou éloignés du consensus. Le graphique qui suit permet ensuite de visualiser ces distances. Plus la distance est faible, plus le sujet est proche du consensus (le barycentre dans l’espace des descripteurs). La valeur 0 correspond à la moyenne sur l’ensemble des sujets. Si, pour un produit donné, tous les sujets donnaient la même note pour tous les descripteurs, le Min et le Max seraient de 0 pour ce produit. Si un sujet donnait pour un produit exactement la valeur correspondant à la moyenne obtenue sur l’ensemble des autres sujets, nous aurions un minimum égal à zéro pour le produit. Dans l'exemple ci-dessous, nous voyons que le sujet 8 n’est pas d'accord avec les autres sujets pour les produits 5 et 14. En revanche, il est d’accord sur les produits 1,3 et 8, où la distance au consensus est plus faible.
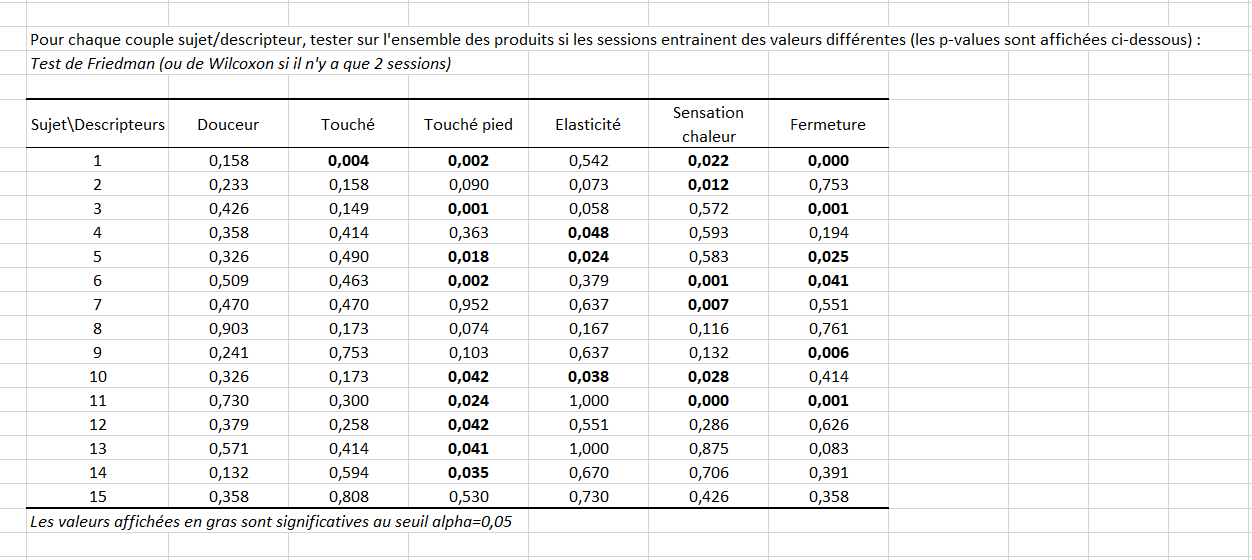
 Comme une variable « Session » a été sélectionnée, la septième étape permet de vérifier d’une seconde manière (non paramétrique) si pour certains sujets il y a un effet ordre de session, au travers d’un test de de Wilcoxon signé (le test de Friedman est utilisé s’il y a plus de deux sessions) calculé sur l’ensemble des produits, descripteur par descripteur. Nous pouvons voir dans le tableau ci-dessous que, pour 4 descripteurs sur un total de 6, il y a un effet de session pour le sujet 1. Nous pouvons également voir que pour le Touché pied, il y a un effet session pour 9 sujets sur 15.
Comme une variable « Session » a été sélectionnée, la septième étape permet de vérifier d’une seconde manière (non paramétrique) si pour certains sujets il y a un effet ordre de session, au travers d’un test de de Wilcoxon signé (le test de Friedman est utilisé s’il y a plus de deux sessions) calculé sur l’ensemble des produits, descripteur par descripteur. Nous pouvons voir dans le tableau ci-dessous que, pour 4 descripteurs sur un total de 6, il y a un effet de session pour le sujet 1. Nous pouvons également voir que pour le Touché pied, il y a un effet session pour 9 sujets sur 15.
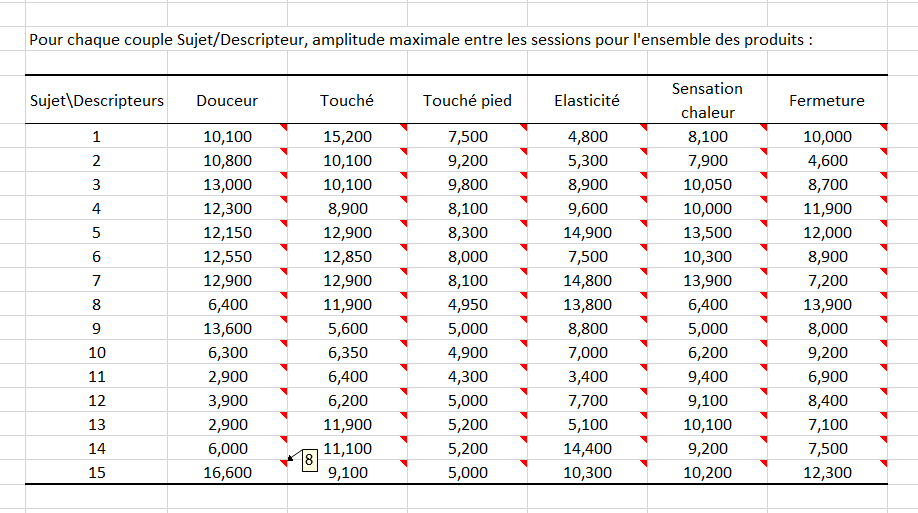
On calcule ensuite pour chaque sujet et chaque descripteur, quelle est l’amplitude maximale observée entre les sessions. Le produit correspondant à l’amplitude maximale est indiqué. Pour voir quel est le produit en question vous devez laisser votre souris sur le triangle rouge affiché dans chaque cellule. Ce tableau permet de repérer d’éventuelles anomalies dans les notes données par certains sujets et éventuellement de supprimer certaines observations pour des analyses futures. Par exemple, nous voyons que l’amplitude maximale est importante pour le sujet 15 pour la Douceur et qu’il correspond au produit 8. Dans notre cas particulier, nous voyons ici qu'il y a des amplitudes élevées pour la plupart des paires (sujet, descripteur). Cela rend la validité de cette enquête douteuse.
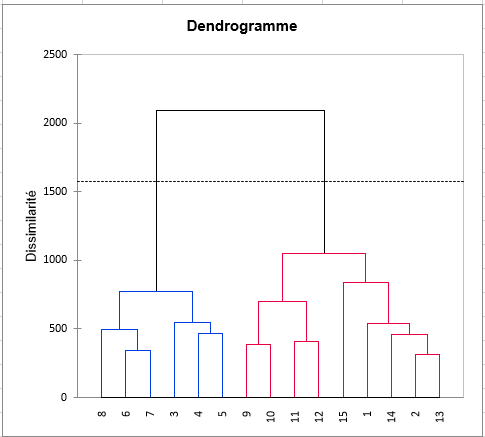
Comme pour chaque triplet (sujet, produit, descripteur) il existe au moins une note, la huitième étape consiste en une classification des sujets. La classification est d’abord réalisée sur les données non centrées-réduites, puis sur les données centrées réduites, afin de supprimer les éventuels effets d’échelle et de position.
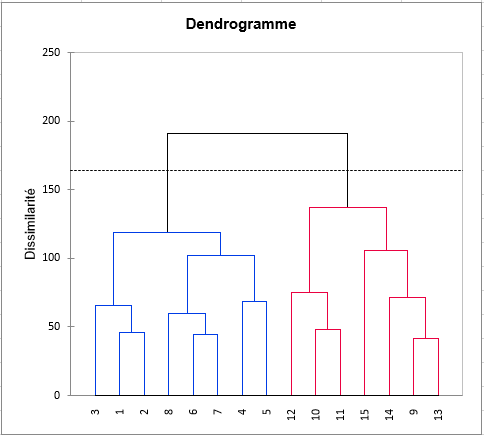
Enfin un tableau préformaté pour utiliser la méthode STATIS est présent. Cette méthode vous permettra d’avoir des indices d’accords entre les sujets et plus généralement d’un sujet avec le point de vue global du panel. De plus, une carte des produits sera réalisée.
Cet article vous a t-il été utile ?
- Oui
- Non