CATA Check-All-That-Apply-Analyse Tutorial in Excel
Dieses Tutorial hilft Ihnen, eine CATA-Analyse in Excel mit der Statistiksoftware XLSTAT einzurichten und zu interpretieren.
Datensatz zur Durchführung einer CATA-Analyse in XLSTAT
Für dieses Tutorial verwenden wir Daten, die von Ares et al. (2014) bereitgestellt wurden. Sie entsprechen der Bewertung von 6 Produkten (5 reguläre und 1 ideales) durch 119 Konsumenten anhand von 15 Attributen. Die Daten sind im binären Format aufgezeichnet (0: Attribut nicht ausgewählt; 1: Attribut ausgewählt). Darüber hinaus wird jedes Produkt (außer dem idealen) von jedem Konsumenten insgesamt (0-10) bewertet.
Die Daten sind im vertikalen Format, was bedeutet, dass wir eine Zeile pro Kombination von Konsument und Produkt haben.
Ziel dieses Tutorials
Dieses Tutorial zielt darauf ab, eine CATA-Analyse (Check-All-That-Apply) durchzuführen, um die von den Konsumenten getesteten Produkte zu charakterisieren.
Einrichten einer CATA-Analyse in XLSTAT
-
Um eine CATA-Analyse durchzuführen, klicken Sie auf Sensorik / CATA-Daten / CATA-Datenanalyse.
-
Stellen Sie im Reiter Allgemein zunächst sicher, dass Sie das Vertikale Datenformat auswählen.
-
Wählen Sie im Feld CATA-Daten die Attributtabelle aus.
-
Wählen Sie dann die Spalten Konsument, Produkt und Präferenz in den Feldern Prüfer, Produkte und Präferenzdaten aus.
-
Geben Sie die Kennung des idealen Produkts im Feld Ideales Produkt ein.
Wichtig: Das Datenset muss ausgeglichen sein (ein Prüfer pro Produkt).
Im Reiter Optionen(1) wählen Sie den Chi-Quadrat-Abstand für die Korrespondenzanalyse, die CATA-Datenvalidierung und die Unabhängigkeit der Attribute.
-
Klicken Sie auf die Schaltfläche OK.
-
Ein Dialogfeld erscheint, um die Achsen auszuwählen und zu validieren, die in der grafischen Darstellung der Korrespondenzanalyse angezeigt werden sollen. Klicken Sie einfach auf die Schaltfläche Fertig.
Interpretation der Ergebnisse einer CATA-Analyse in XLSTAT - Erster Teil
Die ersten beiden Tabellen und Grafiken beziehen sich auf die Validierung der CATA-Daten. Zunächst wird eine Erkennung der Beurteiler durchgeführt, die viel mehr oder weniger als die anderen angekreuzt haben. In unserem Fall haben die meisten Beurteiler zwischen 20 % und 35 % der Zeit angekreuzt, aber einige von ihnen zeigen ein besonderes Verhalten. Zum Beispiel hat Beurteiler 27 nur 7 % der Zeit angekreuzt! Eine ähnliche Attributanalyse wird dann durchgeführt, um über- oder untergenutzte Attribute zu erkennen.
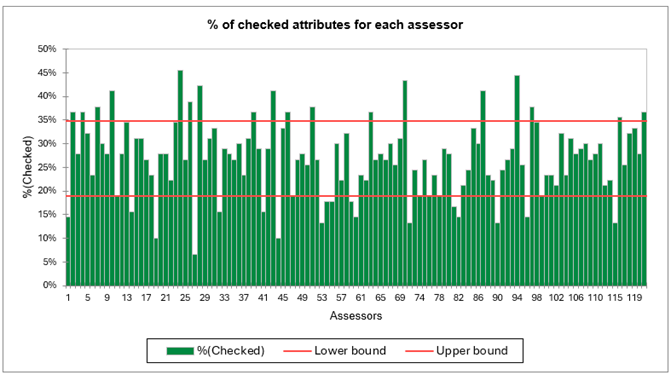
Dann wird eine Analyse durchgeführt, die die beiden vorherigen kombiniert. Sie zeigt den Prozentsatz der Überprüfungen pro Prüfer und Attribut an. Diese Analyse ermöglicht es festzustellen, ob die Attribute einvernehmlich überprüft werden oder nicht. Das Attribut „Saftig“ weist Unterschiede auf, wobei einige Prüfer es mehr als 80 % der Zeit ankreuzen und andere es weniger als 20 % der Zeit ankreuzen.
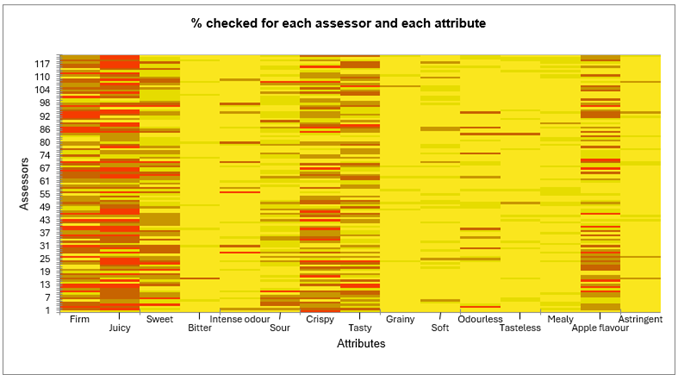
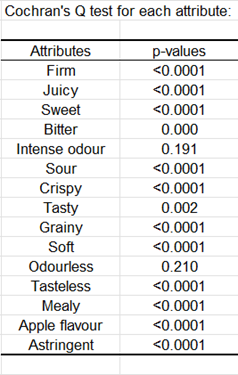
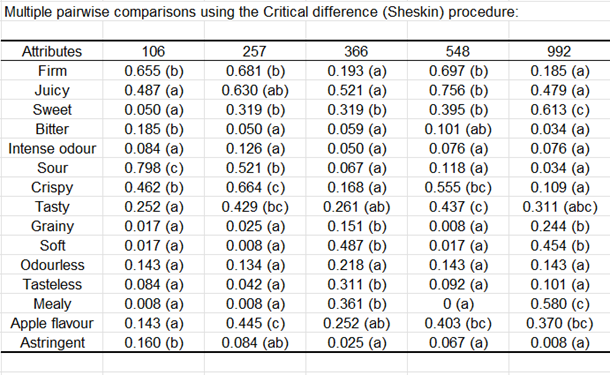
Für ein gegebenes Attribut ermöglicht der Cochran-Q-Test das Testen des Effekts einer erklärenden Variable (Produkte) darauf, ob die Verbraucher das Attribut wahrnehmen oder nicht. Ein niedriger p-Wert jenseits einer Signifikanzschwelle deutet darauf hin, dass sich die Produkte signifikant voneinander unterscheiden. Wenn der p-Wert signifikant ist, könnte der Benutzer daran interessiert sein, mehrere paarweise Vergleiche zu untersuchen, die durch kleine Buchstaben in den Tabellenzellen dargestellt werden:
-
zwei Produkte, die denselben Buchstaben teilen, unterscheiden sich nicht signifikant voneinander.
-
zwei Produkte, die keinen gemeinsamen Buchstaben haben, unterscheiden sich signifikant voneinander.
Wir können sehen, dass alle Attribute außer zwei, die mit dem Geruch zu tun haben (geruchlos und intensiver Geruch), mit signifikanten p-Werten bei 0,05 verbunden sind. Zum Beispiel, wenn wir das Attribut knusprig betrachten, wird das Produkt 257 am häufigsten angekreuzt. Es ist jedoch nicht signifikant knuspriger als das Produkt 548 (überprüfen Sie die Buchstaben). Die Produkte 992 und 366 sind die am wenigsten knusprigen und unterscheiden sich nicht signifikant voneinander.
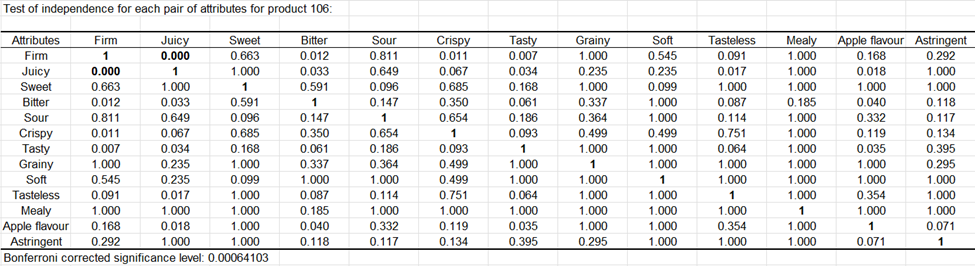
Für jedes der Produkte wird ein Attributunabhängigkeitstest durchgeführt, um festzustellen, ob diese Attribute nicht redundant sind. So können wir sehen, dass für das Produkt 106 die Attribute saftig und fest redundant sind.
Die folgende Kontingenztabelle ist die Summe der Attributtabellen über alle Beurteiler hinweg. Sie wird verwendet, um eine Korrespondenzanalyse (CA) zu erstellen.
Die Unabhängigkeit zwischen den Zeilen und Spalten wird getestet (dieses Ergebnis ist derzeit nur für die klassische CA verfügbar, die die Chi-Quadrat-Distanz verwendet). Da der p-Wert unter dem Signifikanzniveau (0,05) liegt, schließen wir, dass es sehr wahrscheinlich ist, dass tatsächliche Unterschiede zwischen den Produkten in Bezug auf ihre sensorischen Profile bestehen.
Die Tabelle der Eigenwerte und das entsprechende Diagramm ermöglichen es, die Qualität der Analyse zu überprüfen. Die Qualität der Analyse ist gut (92,17 % der erklärten Gesamtträgheit auf den ersten beiden Dimensionen).
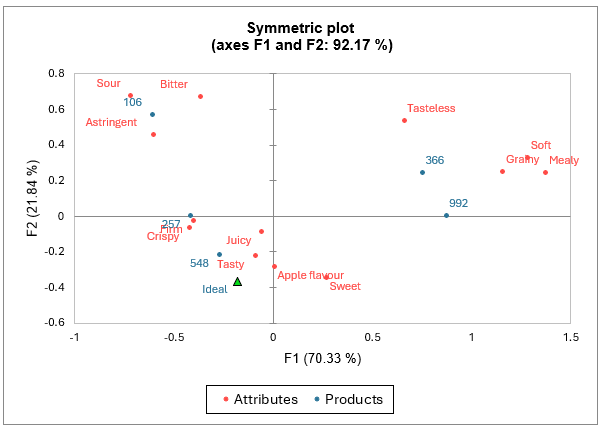
Laut der Analysekarte sollte ein ideales Produkt relativ schmackhaft, saftig, knusprig, fest und süß sein und einen Apfelgeschmack haben.
Andererseits sollte es nicht zu sauer, bitter, adstringierend, körnig, weich, mehlig oder geschmacklos sein. Produkt 548 scheint dem idealen Produkt am nächsten zu kommen, während Produkt 106 aufgrund seiner relativen Bitterkeit, Säure und Adstringenz weit entfernt ist. Auch die Produkte 366 und 992 sind relativ weit vom idealen Produkt entfernt.
Weitere Informationen zur Korrespondenzanalyse finden Sie hier.
Anschließend wird eine Korrelationsmatrix angezeigt, die Attribute (tetrachore Korrelation) und Bewertungsergebnisse (biseriale Korrelation, letzte Zeile) enthält. Wir sehen einige starke Korrelationen. Die negative Korrelation zwischen süß und sauer zeigt, dass wenn Leute sauer ankreuzen, sie süß nicht ankreuzen, und umgekehrt. Die Bewertungsergebnisse scheinen – obwohl schwach – positiv mit den Attributen korreliert zu sein, die im Rahmen der Korrespondenzanalyse dem idealen Produkt zugeordnet wurden (saftig, schmackhaft, Apfelgeschmack).
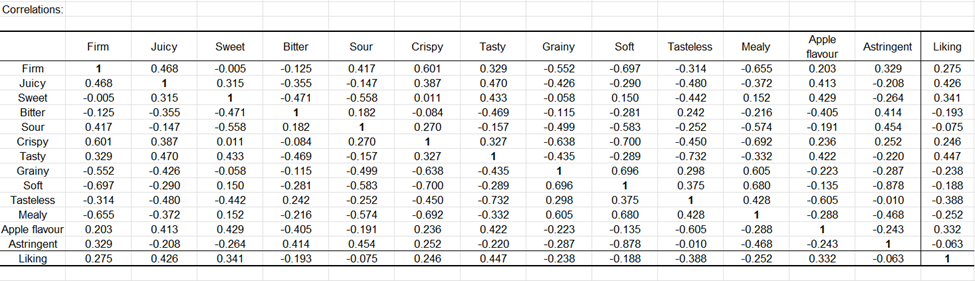
Die Hauptkoordinatenanalyse (PCoA) wird auf die Korrelationskoeffizienten angewendet, und die Ergebnisse werden in einer zweidimensionalen Karte visualisiert. Das Scree-Plot zeigt an, dass die zwei ersten Dimensionen ausreichen, um die Beziehungen zwischen den Attributen zu interpretieren. Hier sehen wir erneut, dass die Bewertung mit den Attributen saftig, schmackhaft und Apfelgeschmack assoziiert ist.
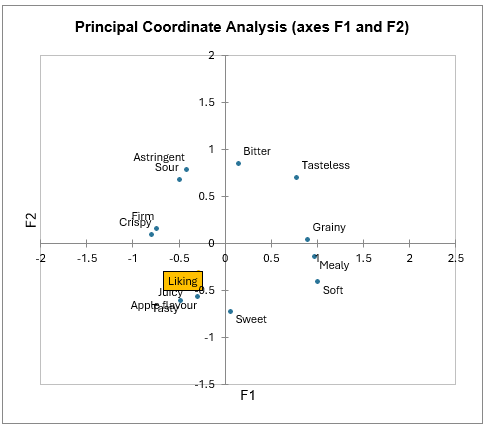
Weitere Informationen zur Hauptkoordinatenanalyse sind hier verfügbar.
Interpretation der Ergebnisse einer CATA-Analyse in XLSTAT - Zweiter Teil
Wenn Präferenzdaten verfügbar sind, beziehen sich die nächsten Ergebnisse auf die Strafanalyse.
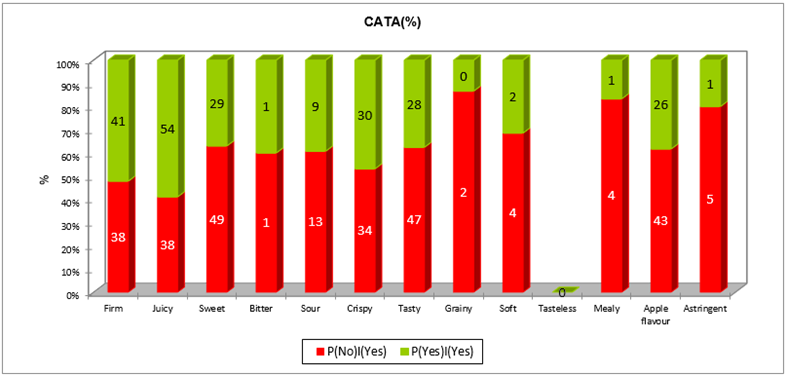
Eine erste Analyse basiert auf der Inkongruenz, bei der das Attribut im realen Produkt fehlt, aber im idealen Produkt vorhanden ist, um die unverzichtbaren Attribute zu identifizieren. Eine Zusammenfassungstabelle zeigt die Häufigkeiten von P(No)|(Yes) und P(Yes)|(Yes) für jedes Attribut. Die folgende grafische Darstellung zeigt diese Häufigkeiten sowie den Prozentsatz der Aufzeichnungen für diese Vorkommen.
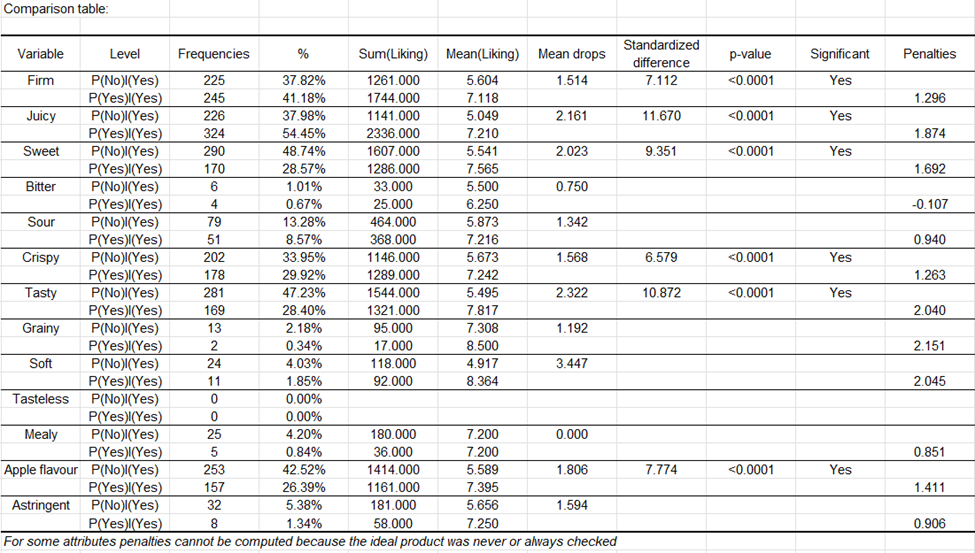
Die durchschnittlichen Rückgänge der Beliebtheit zwischen den beiden Situationen werden dann für jedes Attribut präsentiert und deren Signifikanz getestet. Zum Beispiel impliziert das Attribut „fest“ einen Anstieg von 1,5 Beliebtheitspunkten zwischen den getesteten Produkten und dem idealen Produkt. Dieser Anstieg ist bei 0,05 signifikant (p < 0,0001).
Hinweis: Falls kein ideales Produkt vorhanden ist, wird diese Analyse durch eine Analyse der Anwesenheit und Abwesenheit der Attribute ersetzt.
Das Diagramm des durchschnittlichen Einflusses zeigt die Attribute mit einem signifikanten durchschnittlichen Einfluss. Durchschnittliche Zunahmen werden in Blau angezeigt und als „unverzichtbar“ identifiziert, während durchschnittliche Abnahmen in Rot angezeigt werden.
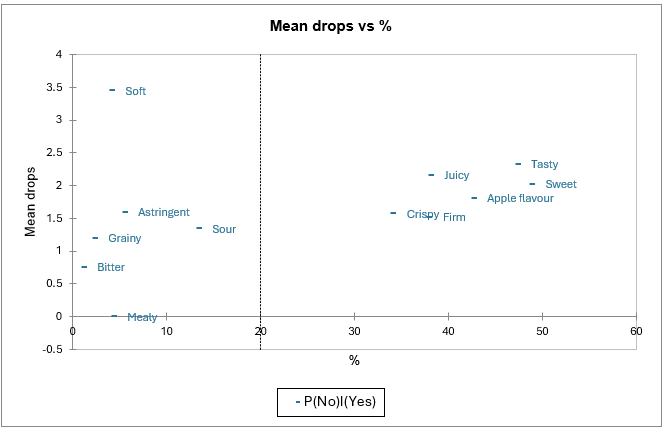
Das Diagramm der durchschnittlichen Rückgänge vs. % ermöglicht ebenfalls eine klare Identifizierung der „unverzichtbaren“ Attribute.
-
Die Y-Achse entspricht den Unterschieden in der Produktbewertung, wenn Verbraucher sowohl ein Produkt als auch das ideale Produkt überprüfen (Zelle [1,1] der „Attributanalyse“-Tabelle) und wenn sie nur das ideale Produkt überprüfen (Zelle [0,1]).
-
Die X-Achse stellt den Prozentsatz der Einträge dar, die eine Überprüfung des idealen Produkts enthalten, ohne dass das tatsächliche Produkt überprüft wird. Dies entspricht einer Situation, in der das Attribut das ideale Produkt gut beschreibt, jedoch relativ wenig in den tatsächlichen Produkten wahrgenommen wird.
Daher erscheinen Attribute, die mit hohen Koordinaten auf beiden Achsen X und Y (lecker, süß, saftig, Apfelgeschmack, knusprig, fest) assoziiert sind, hier erneut als „unverzichtbar“.
Eine zweite Analyse ermöglicht es, die „schönen, aber nicht notwendigen“ Attribute zu identifizieren. Sie ist der ersten ähnlich, basiert jedoch auf der Inkongruenz, bei der das Attribut im idealen Produkt fehlt, aber im tatsächlichen Produkt vorhanden ist.
Hinweis: Diese Analyse ist nur verfügbar, wenn ein ideales Produkt vorhanden ist.
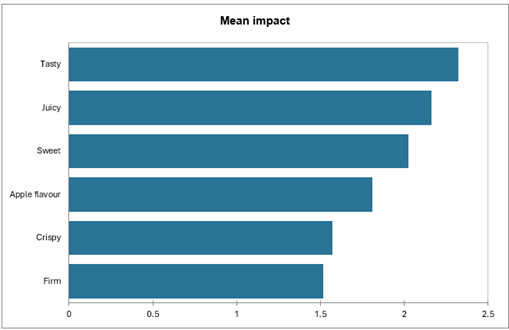
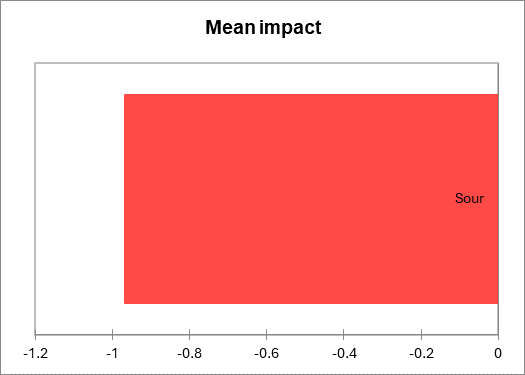
Das Diagramm des mittleren Impacts zeigt die Attribute mit einem signifikanten mittleren Impact. Mittlere Zunahmen werden in Blau angezeigt und als „schön zu haben“ identifiziert, mittlere Abnahmen werden in Rot angezeigt und als „nicht notwendig“ identifiziert. Hier konnte nur das Attribut Sauer analysiert werden.
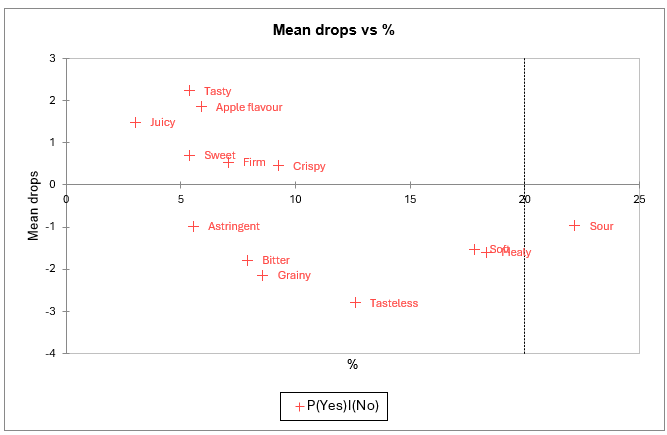
Das Diagramm der mittleren Abnahmen im Vergleich zum Prozentsatz ermöglicht es ebenfalls, die „nicht wünschenswerten“ und „angenehm zu habenden“ Attribute klar zu identifizieren.
-
Die Y-Achse entspricht den Unterschieden in der Produktbewertung, wenn die Verbraucher weder das ideale Produkt noch das tatsächliche Produkt angekreuzt haben (Zelle [0,0] in der Tabelle „Attributanalyse“) und wenn sie das Produkt angekreuzt haben (Zelle [1,0]).
-
Die X-Achse stellt den Prozentsatz der Eingaben dar, bei denen das tatsächliche Produkt angekreuzt wurde, ohne dass das ideale Produkt angekreuzt wurde, was eine Situation beschreibt, in der das Attribut die tatsächlichen Produkte gut beschreibt, aber relativ wenig für das ideale Produkt angekreuzt wird.
Daher erscheinen Attribute, die mit niedrigen Koordinaten auf der Y-Achse verbunden sind (astringierend, bitter, körnig, geschmacklos, weich, mehlig, sauer), hier erneut als „nicht wünschenswert“. Attribute, die mit hohen Koordinaten auf der Y-Achse verbunden sind, sind „angenehm zu haben“.
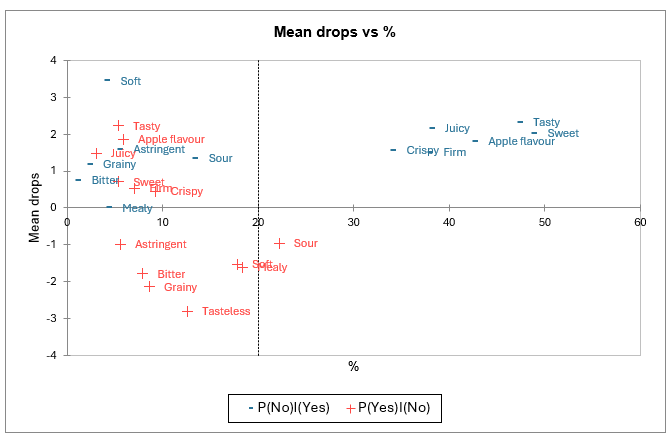
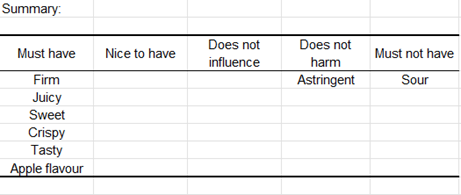
Die beiden vorherigen Analysen werden schließlich in einer einzigen Karte zusammengefasst. Hier erscheinen erneut schmackhaft, süß, Apfelgeschmack, fest, knusprig und saftig als „Must-Have“; und sauer erscheint als „nicht wünschenswert“.
Dann wird für jedes Attribut eine 2x2-Tabelle angezeigt. Auf der linken Seite jeder Tabelle finden sich die Werte für das ideale Produkt, und oben die Werte für die befragten Produkte. In den Zellen der Tabellen finden wir die durchschnittliche Präferenz (durchschnittlich über die Bewerter und die Produkte) und den Prozentsatz aller Aufzeichnungen, die dieser Kombination von 0s und/oder 1s entsprechen.
Für ein bestimmtes Attribut, wenn es für das ideale Produkt angekreuzt wurde (zweite Zeile der Tabelle) und wenn die Präferenz für die angekreuzten Produkte (Zelle [1,1]) signifikant höher ist als die Präferenz für die nicht angekreuzten Produkte (Zelle [1,0]), dann ist das Attribut ein „Must-Have“.
Wenn das Attribut dagegen für das ideale Produkt nicht angekreuzt ist (erste Zeile der Tabelle) und wenn die Präferenz für die nicht angekreuzten Produkte (Zelle [0,0]) signifikant höher ist als die Präferenz für die angekreuzten Produkte (Zelle [0,1]), dann ist das Attribut „zu vermeiden“.
Wenn (Zelle [0,1]) > (Zelle [0,0]) signifikant ist, dann ist das Attribut „schön zu haben“. Wenn das Attribut für das ideale Produkt nicht angekreuzt ist (erste Zeile der Tabelle), weder ein „zu vermeiden“ noch ein „schön zu haben“ ist, und wenn die Präferenz für die angekreuzten Produkte (Zelle [0,1]) vergleichbar ist mit der Präferenz für die nicht angekreuzten Produkte (Zelle [0,0]), dann schadet das Attribut nicht.
XLSTAT betrachtet zwei Produkte als vergleichbar, wenn der absolute Wert ihrer Differenz unter 1 liegt. Schließlich, wenn das Attribut nicht unbedingt erforderlich ist und die Präferenz für die angekreuzten Produkte (Zelle [1,1]) vergleichbar mit der Präferenz für die nicht angekreuzten Produkte (Zelle [1,0]) ist, beeinflusst das Attribut nicht.
Einige Tabellen können den 3 Situationen entsprechen.
XLSTAT wird versuchen, jede 2x2-Tabelle einer einzigen Situation zuzuordnen, indem es sie einer der obigen Regeln zuordnet, wobei diese Reihenfolge beachtet wird.
Bitte beachten Sie, dass XLSTAT zur Entscheidungsfindung hinsichtlich eines Attributs überprüfen wird, ob die gewählte Schwelle für die Populationsgröße (Registerkarte Optionen 2 im Dialogfeld) eingehalten wird. Zum Beispiel werden bei dem Attribut „Fest“ 41 % der befragten (nicht idealen) Produkte sowohl für das befragte Produkt als auch für das ideale Produkt überprüft. Die durchschnittliche Bewertung dieser Aufzeichnungen beträgt 7,1.

In der abschließenden Zusammenfassungstabelle sehen wir, dass 6 der 15 Attribute „unverzichtbar“ sind, 1 „schadet nicht“ und 1 Attribut ist „zu vermeiden“. Die verbleibenden Attribute konnten keiner Kategorie zugeordnet werden.
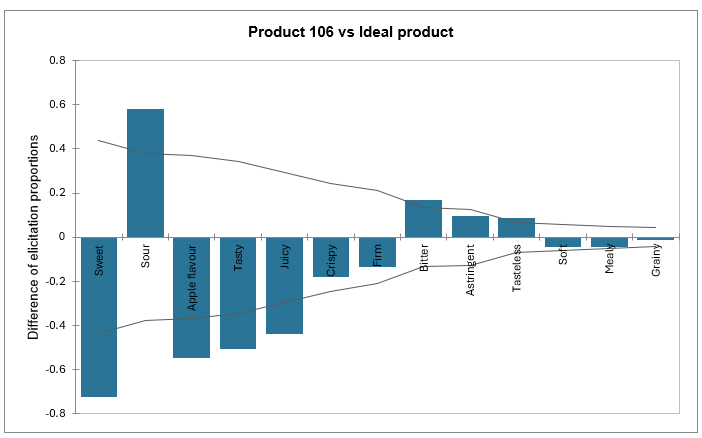
Schließlich sehen Sie eine grafische Darstellung der Erhebungsdifferenz für jedes Produkt im Vergleich zum Ideal. Für jedes Attribut können Sie sehen, ob das Produkt dem Idealprodukt ähnlich oder unterschiedlich ist. Je mehr Unterschiede ein Attribut aufweist, desto problematischer ist es und desto weiter links wird es im Diagramm dargestellt. Im Gegensatz dazu wird die Linie für ein Attribut näher an 0 sein, je ähnlicher das Produkt dem Idealprodukt ist. Wenn die Differenz negativ ist, ist das Attribut nicht ausreichend vorhanden, während es bei einer positiven Differenz zu stark vorhanden ist.
Das Konfidenzintervall wird verwendet, um zu bestimmen, ob die Differenz zum Idealprodukt signifikant ist.
Im Beispiel des Tutorials kann der Wert, der durch die erste Balken im Diagramm 'Produkt 106 vs Idealprodukt' dargestellt wird, wie folgt berechnet werden: (6/119) – (92/119) = 0,0504 – 0,7731 = -0,7227.
Um weiterzugehen
Entdecken Sie eine weitere Methode zur Analyse von CATA-Daten, die in XLSTAT verfügbar ist: CATATIS. Um Verbraucher mit CATA-Daten zu klassifizieren, verwenden Sie bitte die Methode CLUSCATA.
War dieser Artikel nützlich?
- Ja
- Nein