Entrenamiento de una máquina de vector de soporte en Excel
Este tutorial le ayudará a configurar y entrenar un clasificador Máquina de vector de soporte (Support Vector Machine, SVM) en Excel usando el software estadístico XLSTAT.
Datos para entrenar un clasificador SVM
Los datos utilizados en este tutorial se han extraido de la competición sobre aprendizaje automático (Machine Learning) titulada “Titanic: Machine Learning from Disaster” en Kaggle, la famosa plataforma de Data Science.
Puede accederse a los datos Titanic en esta dirección. Se refieren al hundimiento del RMS Titanic en 1912. Durante esa tragedia, más de 1500 de los 2224 pasajeros perdieron la vida debido a un número insuficiente de botes salvavidas.
El conjunto de datos se compone de una lista de 1209 pasajeros junto con alguna información adicional (Nota: se mantienen los nombres de las variables en el inglés original): - survived: Survival (0 = No; 1 = Yes) - Supervivencia (0 = No, 1 = Sí)
- pclass: Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd) - Clase de pasajeros (1 = 1 °, 2 = segundo; 3 = 3 º)
- name: Name - Nombre
- sex: Gender (male; female) - Sexo (varones, mujeres)
- age: Age - Edad
- sibsp: Number of Siblings/Spouses Aboard - Número de hermanos / Cónyuges a bordo
- parch: Number of Parents/Children Aboard - Número de Padres / Niños a bordo
- fare: Passenger Fare - Tarifas de los pasajeros
- cabin: Cabin - Cabina
- embarked: Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton) - Puerto de embarque (C = Cherburgo; Q = Queenstown; S = Southampton)
Objetivo de este tutorial
El objetivo de este tutorial es aprender cómo configurar y entrenar un clasificador SVM sobre el conjunto de datos Titanic y ver con cuánta precisión el clasificador se comporta sobre un conjunto de validación.
Configuración de un clasificador SVM
Para configurar un clasificador SVM, haga clic en Aprendizaje automático / Máquinas de vectores de soporte (SVM) como se muestra a continuación:
 Una vez haya hecho clic en el botón, aparece el cuadro de diálogo SVM. Seleccione los datos en la hoja de cálculo de Excel.
Una vez haya hecho clic en el botón, aparece el cuadro de diálogo SVM. Seleccione los datos en la hoja de cálculo de Excel.
En el campo de la Variable de respuesta, seleccione la variable binaria que queremos predecir la hora de clasificar nuestros datos. En nuestro caso, se trata de la columna que la información de supervivencia.
También seleccionamos ambas variables explicativas cuantitativas y cualitativas marcando las dos casillas como se muestra a continuación.
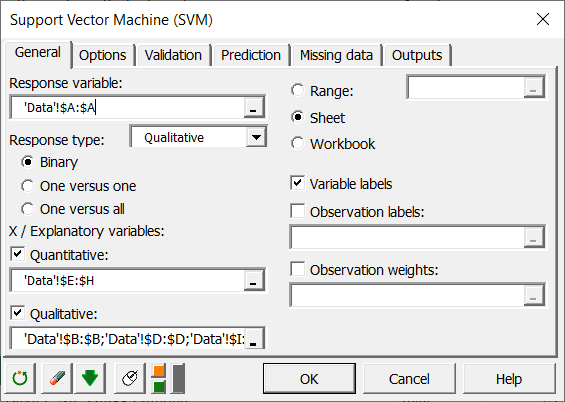 En el campo Cuantitativas, seleccionamos las columnas correspondientes a los siguientes campos: - age
En el campo Cuantitativas, seleccionamos las columnas correspondientes a los siguientes campos: - age
- sibsp
- parch
- fare
Para seleccionar varias columnas, puede usar la tecla Ctrl.
En el campo Cualitativas, seleccionamos las columnas con información cualitativa: - pclass
- sex
- embarked
Puesto que está presente el nombre de cada variable en la parte superior de la tabla, debemos marcar la casilla de verificación Etiquetas de las variables.
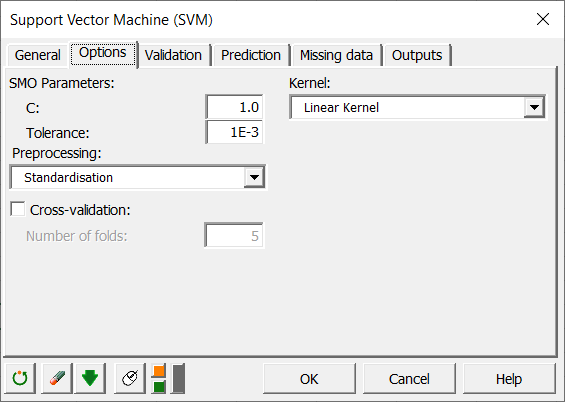
En la pestaña Opciones, se deben configurar los parámetros del clasificador.
En el caso de los parámetros SMO, vamos a dejar las opciones por defecto. El campo C corresponde al parámetro de regularización. Traduce la cantidad de errores de clasificación que deseamos permitir durante la optimización. Un valor grande de C significa una fuerte penalización en cada observación clasificada erróneamente. En nuestro caso, fijamos el valor de C a 1. El campo Epsilon es un parámetro de precisión numérica. Es dependiente de la máquina y se puede dejar en 1e-12. El parámetro de tolerancia indica la precisión del algoritmo de optimización cuando la se comparen los vectores de soporte. Si deseamos acelerar los cálculos, se puede aumentar el parámetro de tolerancia. Dejamos la tolerancia en su valor predeterminado.
Seleccionamos Homotecia (Rescaling) en el campo Pretratamiento (Preprocessing) y utilizamos kernels lineales como se muestra a continuación.
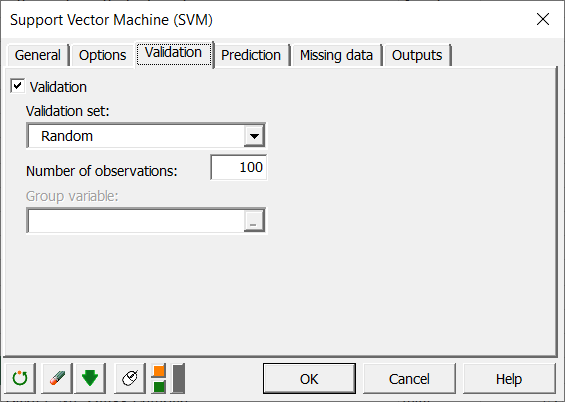
 Dado que queremos ver lo bien que se comporta nuestro clasificador, haremos una muestra de validación a partir de la muestra de entrenamiento. Con este fin, en la pestaña Validación, marcamos la casilla Validación y seleccionamos 100 observaciones extraídas al azar de la población de referencia, como se indica a continuación (por tanto, seleccionamos Aleatorio en Conjunto de validación).
Dado que queremos ver lo bien que se comporta nuestro clasificador, haremos una muestra de validación a partir de la muestra de entrenamiento. Con este fin, en la pestaña Validación, marcamos la casilla Validación y seleccionamos 100 observaciones extraídas al azar de la población de referencia, como se indica a continuación (por tanto, seleccionamos Aleatorio en Conjunto de validación).
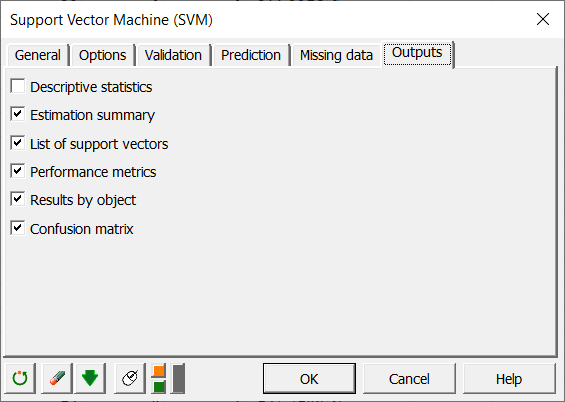
 Por último, en la pestaña Resultados, seleccionamos las salidas que queremos obtener como se muestra a continuación:
Por último, en la pestaña Resultados, seleccionamos las salidas que queremos obtener como se muestra a continuación:
 Los cálculos empiezan una vez haya hecho clic en OK. A continuación, se muestran los resultados.
Los cálculos empiezan una vez haya hecho clic en OK. A continuación, se muestran los resultados.
Interpretación de los resultados del clasificador SVM
La primera tabla muestra un resumen del clasificador SVM optimizado. Se puede ver en la siguiente figura que el clasificador tenía que clasificar entre las clases 0 y 1, y que la clase 0 ha sido etiquetada como la clase positiva. Se usaron 943 observaciones para entrenar al clasificador, de los cuales han sido identificados 456 vectores de soporte.
 La segunda tabla que se muestra a continuación presenta la lista completa de los 456 vectores de soporte junto con los valores de los coeficientes alfa asociados y el valor positivo o negativo de la clase de salida. Junto con el valor de sesgo de la tabla anterior, esta información es suficiente para describir completamente el clasificador optimizado.
La segunda tabla que se muestra a continuación presenta la lista completa de los 456 vectores de soporte junto con los valores de los coeficientes alfa asociados y el valor positivo o negativo de la clase de salida. Junto con el valor de sesgo de la tabla anterior, esta información es suficiente para describir completamente el clasificador optimizado.
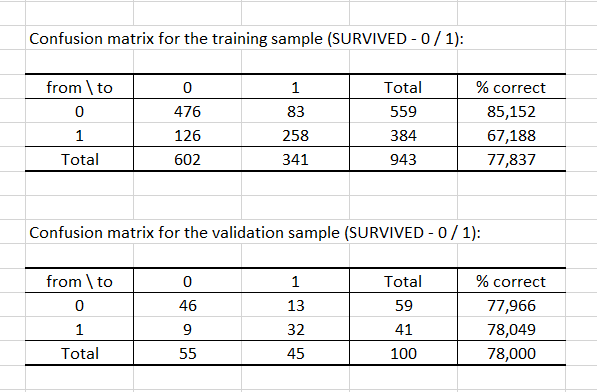
 Las dos tablas siguientes muestran las matrices de confusión resultantes a partir tanto del entrenamiento como de las muestras de validación. Esas matrices nos dan indicios de lo bien que se ha comportado nuestro clasificador. Para la base de datos de entrenamiento, tenemos un 77.84% de respuestas correctas, y esta cifra se eleva hasta el 78% para la base de validación.
Las dos tablas siguientes muestran las matrices de confusión resultantes a partir tanto del entrenamiento como de las muestras de validación. Esas matrices nos dan indicios de lo bien que se ha comportado nuestro clasificador. Para la base de datos de entrenamiento, tenemos un 77.84% de respuestas correctas, y esta cifra se eleva hasta el 78% para la base de validación.
Conclusión de la clasificación SVM
Entrenamos a nuestro clasificador utilizando kernels lineales y obtuvimos bastante buenos resultados, puesto que hemos logrado el 78% de casos correctamente clasificados. Sin embargo, podría resultar necesario llevar a cabo algunos ajustes adicionales, si quisiéramos desafiar al mejor científico de datos en Kaggle. Un enfoque podría ser cambiar la familia de kernel y comprobar la precisión adicional que un espacio de dimensión superior podría aportar a la clasificación de nuestros datos.
¿Ha sido útil este artículo?
- Sí
- No