Classification des sujets dans une épreuve CATA avec CLUSCATA dans Excel
Ce tutoriel explique comment réaliser et interpréter une classification des sujets dans une épreuve CATA grâce à la méthode CLUSCATA avec Excel en utilisant XLSTAT.
Jeu de données à analyser avec CLUSCATA
Les données utilisées pour illustrer la méthode CLUSCATA se rapportent à une expérience Check-All-That-Apply (CATA) où 114 consommateurs ont évalué 6 fraises à l'aide de 16 attributs (Ares & Jaeger, 2013). Les consommateurs ont été invités à cocher, parmi les attributs proposés, ceux qui s’appliquaient pour décrire chacune des fraises.
But de ce tutoriel
Le but ici est de réaliser une analyse des données en trois temps :
- Segmenter les sujets en fonction de leurs perceptions des produits. Des classes les plus homogènes possibles vont être constituées grâce à la méthode CLUSCATA.
- Analyser chaque classe de sujets par la méthode CATATIS afin de déterminer les différences de perceptions des fraises entre les classes.
- Déterminer des indices de qualité de la classification.
Nous utiliserons la fonction CLUSCATA de XLSTAT pour faire cette analyse. Cet outil nous permettra de réaliser les trois objectifs définis ci-dessus.
Paramétrer la boîte de dialogue de CLUSCATA
Une fois XLSTAT lancé, sélectionnez le menu XLSTAT / Fonctions avancées / Analyse de données sensorielles/ CLUSCATA.
La boîte de dialogue CLUSCATA apparaît.
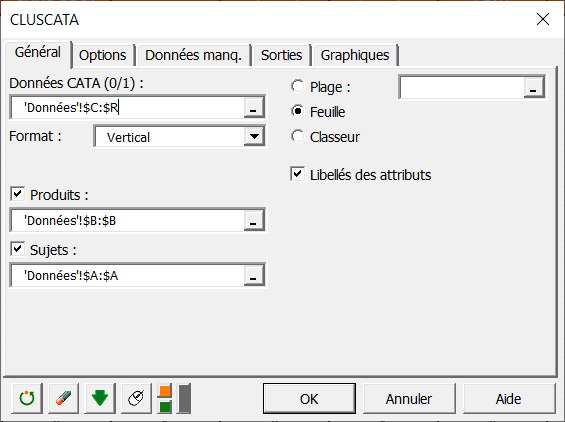
Dans l’onglet Général, vous pouvez alors sélectionner les données CATA (l’ensemble de vos données concaténées).
Le Format indique comment vous avez concaténé vos données, cela peut-être de façon horizontale ou verticale.
Si le Format est horizontal, vous devez indiquer le nombre de juges, et s’il est vertical, les sélections des Produits et des Juges sont obligatoires.
Ici nos données sont concaténées de façon verticale, et nous sélectionnons donc les Produits et les Juges. De plus, nous avons des libellés pour les attributs, nous cochons donc la case Libellés des attributs pour l’indiquer à XLSTAT.
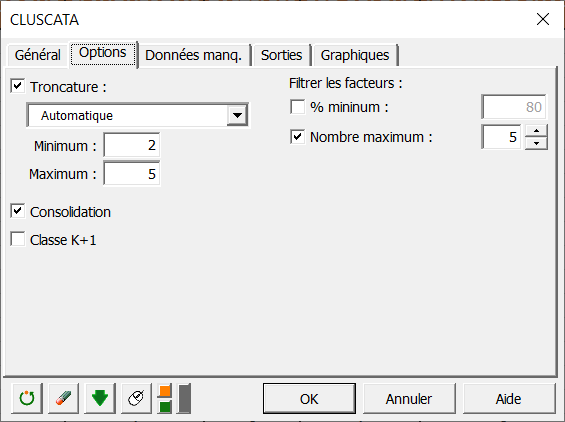
Dans l’onglet Options, nous avons décidé de laisser le choix du nombre de classes automatique, et d’appliquer une consolidation des classes obtenues par l’algorithme hiérarchique afin obtenir une classification plus précise.
Dans l’onglet Graphiques, si vous sélectionnez la case Graphiques sur les deux premiers axes, vous aurez automatiquement la représentation des différentes cartes sur les 2 premiers axes factoriels. Si vous le décochez, une fenêtre s’ouvrira alors et vous pourrez choisir vos axes pour chaque classe.
Interpréter les résultats d’une analyse CLUSCATA
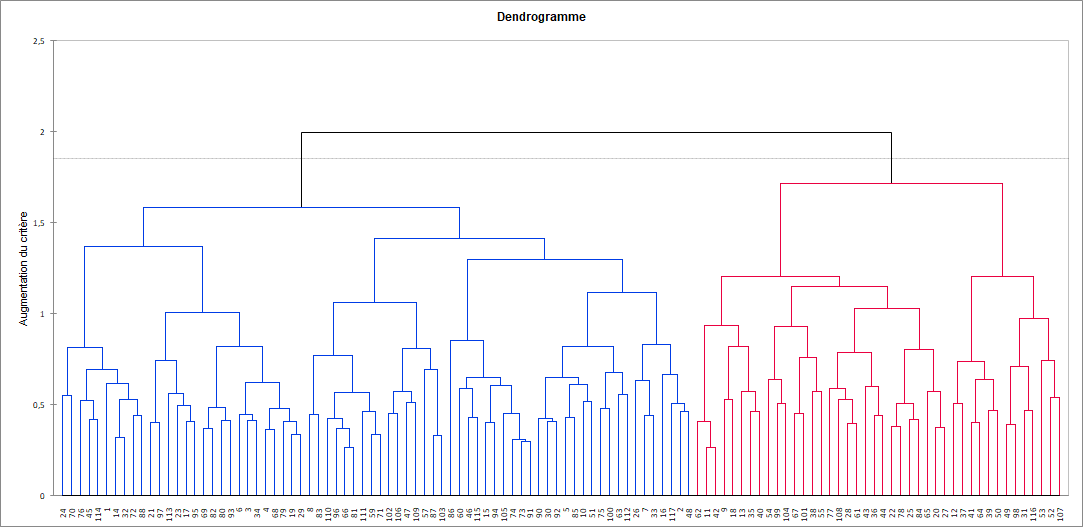
Le graphique ci-dessous est le dendrogramme. Il représente de manière claire la façon dont l'algorithme procède pour regrouper les sujets puis les groupes de sujets. L'algorithme a progressivement regroupé tous les sujets. La ligne en pointillé représente la troncature et permet de visualiser que deux classes ont été identifiées.
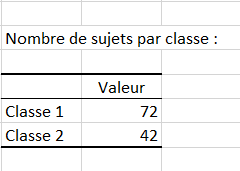
Il s’en suit trois tableaux, donnant les résultats par des groupes par sujet, par classe ainsi que le nombre de sujets dans chaque classe. Nous pouvons ici voir que la classe 1 contient bien plus de sujets que la classe 2.
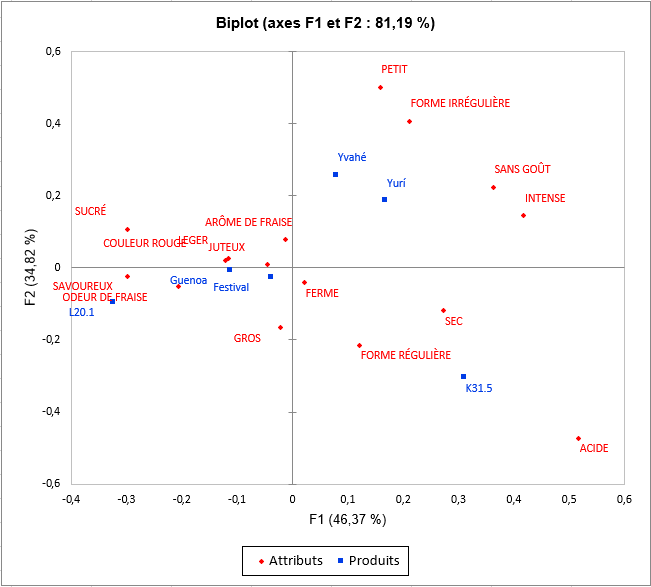
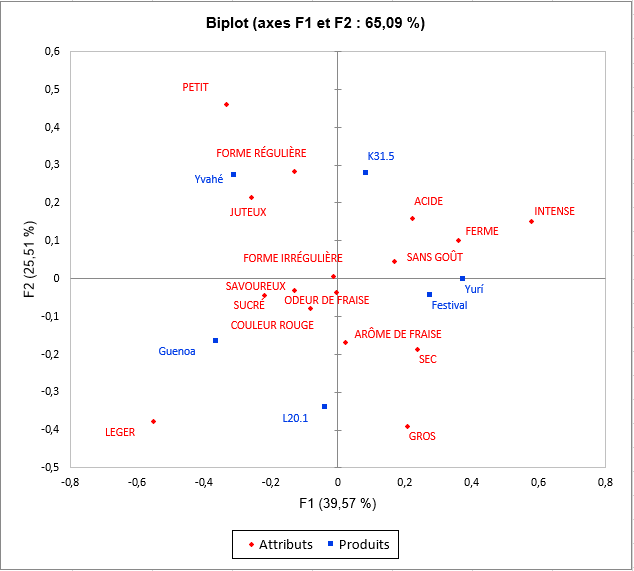
Viens ensuite l’analyse de chacune des classes construites. La représentation des produits et des attributs dans chaque classe met en lumière des différences de perception entre les classes de sujets. En effet, les fraises Yvahé et Yurí sont placées ensemble dans la classe 1 et sont considérées comme différentes dans la classe 2. Nous pouvons également noter que la fraise Yvahé est considérée plutôt de forme irrégulière dans la classe 1 et de forme régulière dans la classe 2.
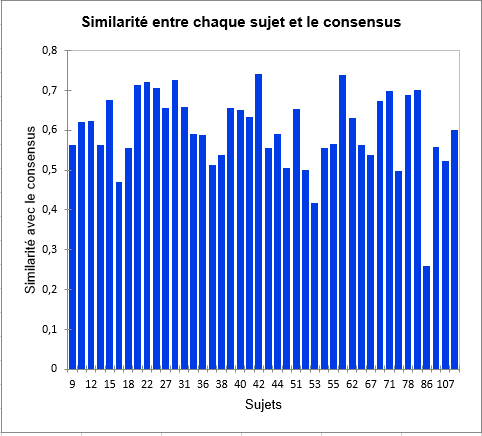
Le graphique suivant donne des indications sur la proximité des sujets et du tableau consensus de la classe dans laquelle ils sont placés. Ces proximités sont représentées par le coefficients de similarité d’Ochiai, qui est un indice de similarité entre 0 et 1. Dans la classe 2, nous pouvons observer que le sujet 86 est bien plus éloigné du consensus que les autres, ce qui signifie qu’il ne se conforme pas bien à la classe. Sa perception est différente des deux classes (puisqu’il a été placé dans la classe qui lui correspond le mieux par l’algorithme). Ce genre de problématique peuvent être résolues par l’ajout de la classe « K+1 » dans l’onglet Options, qui est une classe supplémentaire prévue pour mettre de côté les sujets atypiques. Attention, dans une épreuve CATA, il est très fréquent de mettre de côté une grande partie des sujets avec la classe « K+1 ». Ceci est dû au fait que les sujets donnent des résultats souvent bien différents.
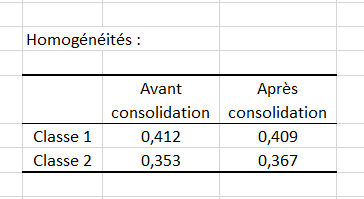
Enfin, l’indice d’homogénéité de chaque classe permettent d’évaluer la qualité de la classification. Plus ces indices sont proches de 1, plus les classes sont homogènes. Ici, nous voyons que la classe 1 est plus homogène que la classe 2. Ces homogénéités pourraient être améliorées avec l’ajout d’une classe « K+1 ».
Cet article vous a t-il été utile ?
- Oui
- Non