Analyse Sémantique Latente (LSA) dans Excel
Ce tutoriel explique comment calculer et interpréter une analyse sémantique latente ou Latent Semantic Analysis (LSA) avec Excel en utilisant XLSTAT.
Jeu de données pour réaliser une analyse sémantique latente
Dans ce tutoriel, nous utiliserons une matrice documents-termes générée via la fonctionnalité XLSTAT Extraction de caractéristique dont les données textuelles initiales sont une compilation de commentaires laissés sur plusieurs plateformes de vente de vêtements en ligne. L’analyse est volontairement restreinte à 5000 lignes choisies aléatoirement dans le jeu de données.
But de ce tutoriel
Le but est ici de construire des groupes homogènes de termes afin d’identifier des thématiques contenus dans cet ensemble de documents décrit via une matrice documents-termes (D.T.M).
C’est une méthode simple et efficace pour l’extraction de relations conceptuelles (facteurs latents) entre termes. Cette méthode se base sur une méthode de réduction de dimension de la matrice d’origine (Décomposition en valeurs singulières).
L’analyse sémantique latente ici présentée est une façon de capturer les « dimensions » sémantiques principales dans le corpus de textes, ce qui permet de détecter les principaux « sujets » et de résoudre, parallèlement, la question de la synonymie et de la polysémie.
Paramétrer la boîte de dialogue de l’analyse sémantique latente
Une fois que XLSTAT est ouvert, choisissez XLSTAT / Fonctions avancées / Text mining / Analyse sémantique latente (voir ci-dessous).
 Une fois le bouton cliqué, la boîte de dialogue correspondant à l’Analyse sémantique latente apparaît.
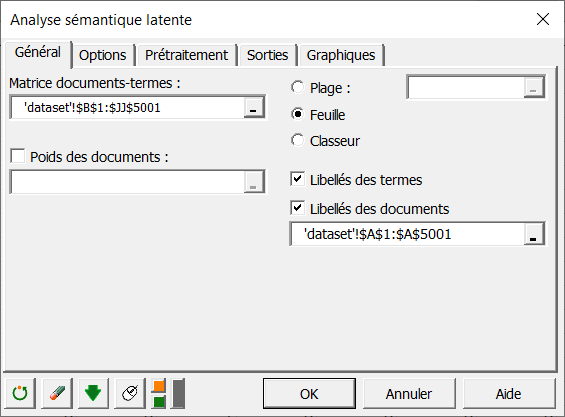
Vous pouvez alors sélectionner les données via le champ Matrice documents-termes (sélection de cellules dans Excel). L'option Libellés des documents est activée, et on sélectionne la première colonne du tableau de données contenant le nom des documents. L'option Libellés des termes est également activée, car la première ligne de données contient le nom des termes.
Une fois le bouton cliqué, la boîte de dialogue correspondant à l’Analyse sémantique latente apparaît.
Vous pouvez alors sélectionner les données via le champ Matrice documents-termes (sélection de cellules dans Excel). L'option Libellés des documents est activée, et on sélectionne la première colonne du tableau de données contenant le nom des documents. L'option Libellés des termes est également activée, car la première ligne de données contient le nom des termes.
 Dans l'onglet Options, nous fixons le nombre de thématiques à 30 dans le but de faire apparaître le plus de sujets possibles pour cet ensemble de documents mais aussi d’obtenir une variance expliquée convenable sur la matrice réduite calculée.
Dans l'onglet Options, nous fixons le nombre de thématiques à 30 dans le but de faire apparaître le plus de sujets possibles pour cet ensemble de documents mais aussi d’obtenir une variance expliquée convenable sur la matrice réduite calculée.
On choisira d’activer les options regrouper par document ainsi que regrouper par terme afin de créer des classes de documents et de termes dans le nouvel espace sémantique. L’option absolue choisie ici force chacun des termes à appartenir à un et un seul thème à la fois (le meilleur axe sémantique).
Une classification Floue au contraire va autoriser un terme à appartenir simultanément à plusieurs thématiques afin de capturer la polysémie (terme ayant plusieurs sens).
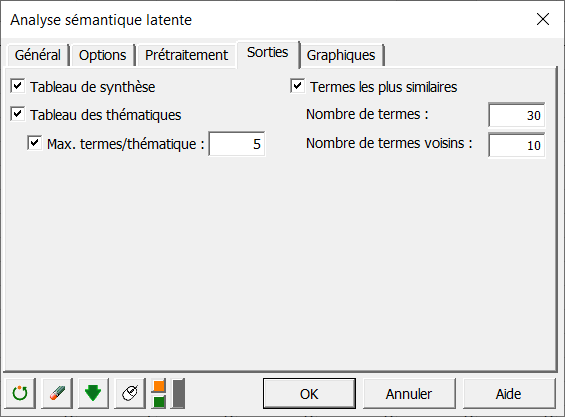
 Dans l'onglet Sorties, nous fixons le nombre maximal de termes par thématique (Max. termes/thématique) à 5 dans le but de ne visualiser uniquement que les meilleurs termes de chaque thématique dans le tableau des thématiques ainsi que dans les différents graphiques correspondant aux matrices de corrélation (Voir l’onglet Graphiques).
Dans l'onglet Sorties, nous fixons le nombre maximal de termes par thématique (Max. termes/thématique) à 5 dans le but de ne visualiser uniquement que les meilleurs termes de chaque thématique dans le tableau des thématiques ainsi que dans les différents graphiques correspondant aux matrices de corrélation (Voir l’onglet Graphiques).
L’option Termes les plus similaires est activée afin de visualiser les corrélations terme à terme (similarités cosinus) relatives à chacun des termes du corpus.
Le Nombre de termes est fixé à 30 afin de n’afficher que les 30 meilleurs termes toutes thématiques confondues dans la liste déroulante (par ordre décroissant de relation avec les axes sémantiques).
Le Nombre de termes voisins est fixé à 10 afin de ne visualiser que les 10 termes les plus similaires avec le terme sélectionné dans la liste déroulante.
Les calculs commencent lorsque vous cliquez sur le bouton OK.
Interpréter les résultats de l’analyse sémantique latente
Le tableau de synthèse ci-dessous présente pour chacune des thématiques, le nombre total de termes et documents les composant.
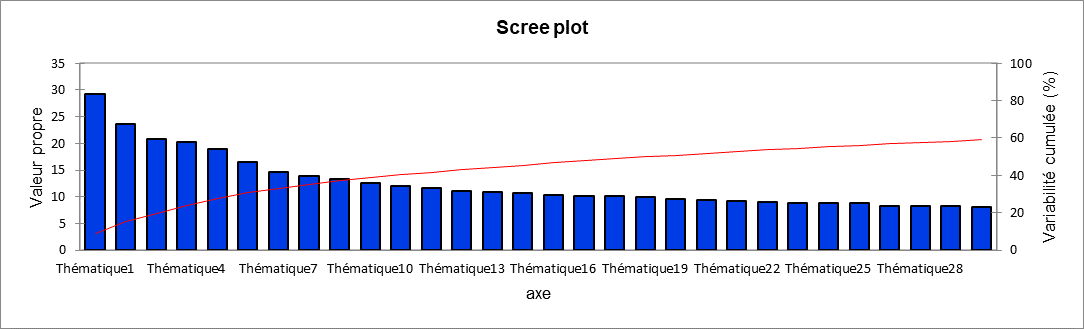
L'utilisateur a ainsi la possibilité par la suite d'afficher l'intégralité des termes/documents dans les graphiques liés aux matrices de corrélation ainsi que dans le tableau des thématiques. Le tableau suivant ainsi que le graphique associé sont liés à un objet mathématique, les valeurs propres, dont chacune correspond à l’importance d’une thématique.
Le tableau suivant ainsi que le graphique associé sont liés à un objet mathématique, les valeurs propres, dont chacune correspond à l’importance d’une thématique.
La qualité de la projection lorsque l'on passe de N dimensions (N étant le nombre de termes total au départ, 269 dans ce jeu de données) à un nombre plus faible de dimensions (30 dans notre cas) est mesurée via le pourcentage cumulé de variabilité.
A chaque valeur propre correspond donc une thématique et on voit ici qu’une dimension 30 permet d’obtenir une variabilité cumulée totale d’environ 60% de la matrice initiale.

 Le tableau ci-dessous liste les meilleurs termes de chacune des thématiques trouvées. Ces derniers sont affichés par ordre décroissant d’importance avec le thème en question.
Le tableau ci-dessous liste les meilleurs termes de chacune des thématiques trouvées. Ces derniers sont affichés par ordre décroissant d’importance avec le thème en question.
Ce premier résultat met en évidence des classes d’éléments souvent associées à des sentiments positifs ou bien négatifs au sujet d’aspects particuliers des vêtements achetés en ligne.
A titre d’exemple, les thématiques 8 et 24, composées entre autres des paires de mots {small, large} et {run, bust} relatent des problèmes de taille sur des lignes de vêtements. Ces paires peuvent donc être combinées pour ne faire plus qu’un terme commun afin de symboliser cela et ainsi éliminer les redondances sémantiques (synonymie) dans la matrice documents-termes initiale.
La thématique 6 fait quant à elle un constat de réussite en associant un sentiment positif{sweet} avec une gamme de vêtements {top, peplum}.

L’intensité des relations pour chaque paire de termes est représentée visuellement via le graphique des corrélations ci-dessous. Il permet de visualiser le degré de similarité (similarité cosinus) entre les termes dans le nouvel espace sémantique créé. La normalisation en similarité cosinus permet de comparer des termes avec des fréquences d’apparition différentes.
Les similarités sont comprises entre 0 et 1, la valeur 1 correspondant à une similarité/dissimilarité parfaite (similarité en cas d’accord et dissimilarité en cas de désaccord).
Les termes sont affichés dans l’ordre des classes thématiques trouvées (ces classes peuvent en outre être visualisées en activant l’option « colorer les classes » sous l’onglet Graphiques).
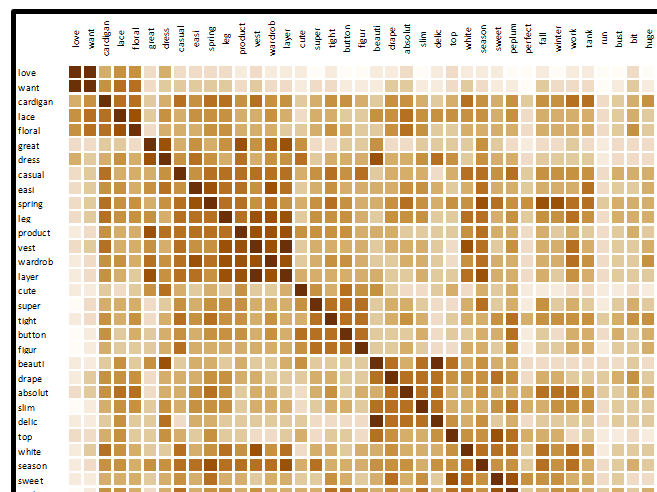
Les deux exemples ci-dessous montrent les similarités des termes les plus proches aux termes sélectionnés (ici top et run) dans la liste déroulante dans le nouvel espace sémantique créé et ce par ordre décroissant de similarité.

 En conclusion, voici un exemple d’application de l’analyse sémantique latente où les classes créées vont permettre de combiner des termes exprimant une caractéristique (taille de vêtements par exemple) ou un sentiment (négatif ou positif) similaires. Afin d’appliquer une réduction dimensionnelle sur la matrice DTM d’entrée, tout en conservant un bonne variance (cf. tableau des valeurs propres), vous pouvez récupérer les termes les plus influents pour chacune des thématiques dans le tableau des thématiques. Cela permet d'appliquer par la suite un algorithme d’apprentissage de manière plus efficace.
En conclusion, voici un exemple d’application de l’analyse sémantique latente où les classes créées vont permettre de combiner des termes exprimant une caractéristique (taille de vêtements par exemple) ou un sentiment (négatif ou positif) similaires. Afin d’appliquer une réduction dimensionnelle sur la matrice DTM d’entrée, tout en conservant un bonne variance (cf. tableau des valeurs propres), vous pouvez récupérer les termes les plus influents pour chacune des thématiques dans le tableau des thématiques. Cela permet d'appliquer par la suite un algorithme d’apprentissage de manière plus efficace.
Cet article vous a t-il été utile ?
- Oui
- Non