Diskriminanzanalysen (PLSDA) in Excel - Anleitung
Dieses Tutorium wird Ihnen helfen, eine Partielle Kleinste Quadrate Diskriminanzanalyse in Excel mithilfe der XLSTAT Software einzurichten und zu interpretieren.
Sie sind nicht sicher, ob es sich hierbei um die Modellierungsfunktion handelt, nach der Sie suchen? Weitere Hinweise finden Sie hier.
Datensatz für das Durchführen einer teilweisen kleinsten Quadrate Diskriminanzanalyse
Ziel der teilweisen kleinsten Quadrate Diskriminanzanalyse in diesem Beispiel
Ziel ist es zu überprüfen, ob die vier Variablen es erlauben, die Spezies zu unterscheiden und die Beobachtungen in einer 2-dimensionalen Karte darzustellen, um so gut wie möglich darzustellen, wie gut die Gruppen unterschieden werden. Dies basiert auf der teilweisen kleinsten Quadrate-Methode und erlaubt es kollineare Daten, fehlende Daten und Datensätze mit wenigen Beobachtungen und vielen Variablen zu untersuchen.
Einstellungen der teilweisen kleinsten Quadrate Diskriminanzanalyse
Nach dem Öffnen von XLSTAT, wählen Sie den Befehl XLSTAT / Modellierung der Daten / Partial Least Squares Regression, oder klicken Sie auf den zugehörigen Button im Menu Modellierung der Daten (siehe unten).
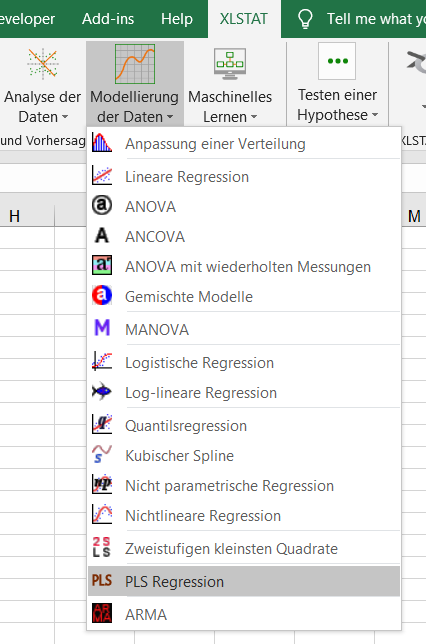
Nach dem Klicken des Buttons, erscheint das Dialogfenster der Partial Least Squares regression.
Im Feld der Abhängigen Variablen wählen Sie mit der Maus die Spezies.
Im Feld der Abhängigen Variablen wählen Sie mit der Maus die erklärenden Variablen, die in unserem Fall die physikalische Beschreibung der Iris darstellt.
Die verwendete Methode ist die PLS-DA für die teilweise kleinste Quadrate Diskriminanzanalyse.
Im Reiter Optionen des Dialogfensters, wählen Sie die Option Automatisch aus.
Zuletzt aktivieren Sie im Reiter Diagramme die Option Farbige Beschriftungen, um die Diagramme besser lesen zu können.
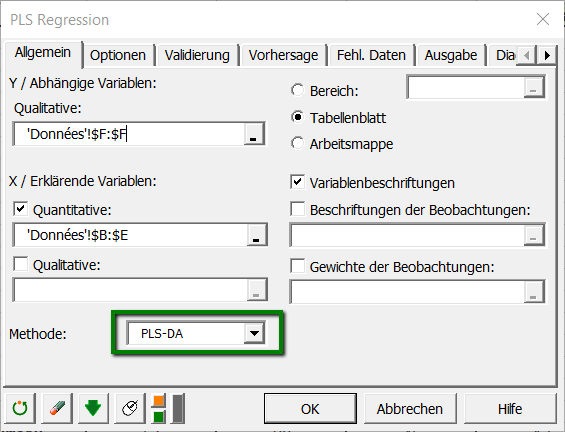
Starten Sie die Berechnungen mittels des Button OK. Die Ergebnisse werden in einem neuen Excelblatt angezeigt.
Interpretation der Ergebnisse der Diskriminanzanalyse
Die ersten angezeigten Ergebnisse sind die klassischen PLS Regressionsergebnisse zwischen den erklärenden Variablen und den Spezies (jede Spezies wird durch eine einzelne Variable dargestellt).
Nach den Tabellen der einfachen Statistiken und den Korrelationen zwischen den ausgewählten Variablen (abhängige Variablen werden in blau dargestellt und quantitative abhängige Variablen in schwarz), anschließend werden die spezifischen Ergebnisse der PLS-Regression angezeigt.

Der Q² kumulierter Index misst die globale Anpassungsgüte und die prädiktive Qualität der 3 Modelle (eines für jede Spezies).
XLSTAT-PLS wählte automatisch 4 Komponenten. Man sieht, dass Q² klein bleibt, auch mit 4 Komponenten (idealerweise sollte er nah bei 1 liegen). Dies unterstellt, dass die Qualität der Anpassung stark von der betrachteten Spezies abhängt.
Die kumulierten R²Y und R²X, die den Korrelationen zwischen den erklärenden (X) und den abhängigen (Y) Variablen mit den Komponenten entsprechen sind nahe bei 1 mit 4 Komponenten. Die bedeutet, dass die 4 von der PLS-Regression generierten Komponenten gut die Variablen der X und der Y zusammenfassen.
Die erste Korrelationenkarte erlaubt es die Korrelationen für die ersten beiden Komponenten zwischen den X Variablen und den Komponenten und zwischen den Y Variablen und den Komponenten anzuzeigen.

Man kann die Spezies und die erklärenden Variablen in einem Korrelationsplot darstellen.
Nachdem die klassischen PLS Regressionsergebnisse angezeigt worden sind, werden die spezifischen Ergebnisse der PLS Diskriminanzanalyse dargestellt.
Die nächste Tabelle fasst den Klassifikationsprozess zusammen. Jede Beobachtung wird der Gruppe zugeordnet, deren Zugehörigkeitswahrscheinlichkeit am größten ist.. Man kann sehen, dass zwei Beobachtungen (3 und 5) erneut klassifiziert wurden. Es gibt verschiedene Interpretationsmöglichkeiten der Ergebnisse: Zum einen könnte die Person, die die Messungen vornahm Fehler bei der Aufzeichnung der Werte begangen haben oder die entsprechenden Schwertlilienblüten hatten einen ungewöhnlichen Wuchs oder die Kriterien des Spezialisten zur Bestimmung der Spezies sind nicht präzise genug oder noch notwendige Informationen zur Diskriminierung der Blumen sind in diesem Fall nicht verfügbar.

Die folgenden Grafiken stellen die Beobachtungen auf den t-Achsen dar. Dies erlaubt es zu überprüfen, ob alle Spezies gut diskriminiert auf den Faktorachsen extrahiert aus den Ausgangsvariablen wurden.

Zuletzt fasst die Konfusionsmastrix die Klassifizierung der Beobachtungen zusammen und erlaubt er schnell die Einordnungsfehlerrate zu sehen, die dem Quotienten aus der Anzahl der Beobachtungen, die falsch klassifiziert wurden, und der Gesamtzahl der Beobachtungen an. In diesem Fall beträgt sie 85 %.

XLSTAT-PLS erlaubt es Ihnen Vorhersagewerte für einen Validierungsdatensatz für die PLS Diskriminanzanalyse zu berechnen.
War dieser Artikel nützlich?
- Ja
- Nein