Régression logistique binaire dans Excel
Ce tutoriel explique comment mettre en place et interpréter une régression logistique binaire dans Excel avec XLSTAT.
Régression logistique
La régression logistique, et les méthodes associées comme l'analyse Probit, sont très utiles lorsque nous souhaitons comprendre ou prédire l'effet d'une ou plusieurs variables sur une variable à réponse binaire, c'est à dire qui ne peut prendre que deux valeurs 0/1 ou Oui/Non par exemple.
Une régression logistique sera très utile pour modéliser l'effet de doses de médicament en médecine, de doses de composants chimiques en agriculture, ou pour évaluer la propension de clients à répondre à un mailing, ou encore pour mesurer le risque pour qu'un client ne rembourse pas son prêt dans une banque.
Avec XLSTAT, il est possible de faire de la régression logistique soit directement sur les données brutes (la réponse est 0 ou 1) soit sur des données agrégées (la réponse est une somme de succès - de 1 par exemple - et dans ce cas le nombre de répétitions doit aussi être disponible). La régression logistique permet de modéliser la probabilité qu'un événement survienne étant donné les valeurs d'un ensemble de variables descriptives quantitatives et/ou qualitatives.
Jeu de données pour la régression logistique
L'exemple que nous traitons ci-dessous correspond à un cas marketing dans lequel on cherche à prédire la probabilité pour qu'un client renouvelle son abonnement à un service d'information en ligne. Les données correspondent à un échantillon de 60 lecteurs, avec la catégorie d'âge, le nombre moyen de pages vues par semaine sur les 10 dernières semaines, et le nombre de pages vues au cours de la dernière semaine. Il a été proposé à ces lecteurs de renouveler leur abonnement qui doit expirer dans deux semaines. L’objectif est de comprendre pourquoi certains ont re-souscrit d'autres non.
But de ce tutoriel sur la régression logistique
Le but est d'utiliser la régression logistique pour dans un premier temps comprendre les résultats obtenus, et ensuite pour appliquer le modèle sur l'ensemble de la population afin d'identifier les personnes qui pourraient ne pas renouveler leur abonnement. Grâce à ces informations, le responsable marketing pourra leur proposer une promotion ou des services complémentaires afin de stimuler leur intérêt pour l'offre.
Paramétrer une régression logistique
Pour activer la boîte de dialogue de la régression logistique, lancez XLSTAT, puis choisissez XLSTAT / Modélisation des données / Régression logistique.
Une fois que vous avez cliqué sur le bouton, la boîte de dialogue apparaît. Sélectionnez les données sur la feuille Excel.

Les données Réponse correspondent à la colonne dans laquelle se trouve la variable binaire ou quantitative (résultant alors d'une somme de binaires - dans ce cas la colonne des "Poids" doit ensuite être sélectionnée).
Dans notre cas il y a trois variables explicatives, une qualitative - la classe d'âge - et deux quantitatives correspondant aux comptages des pages vues.
Comme nous avons sélectionné les libellés des variables, nous devons sélectionner l'option Libellés des variables.
Une fois que vous avez cliqué sur le bouton OK, les calculs sont effectués puis les résultats affichés.
Interpréter les résultats d'une régression logistique
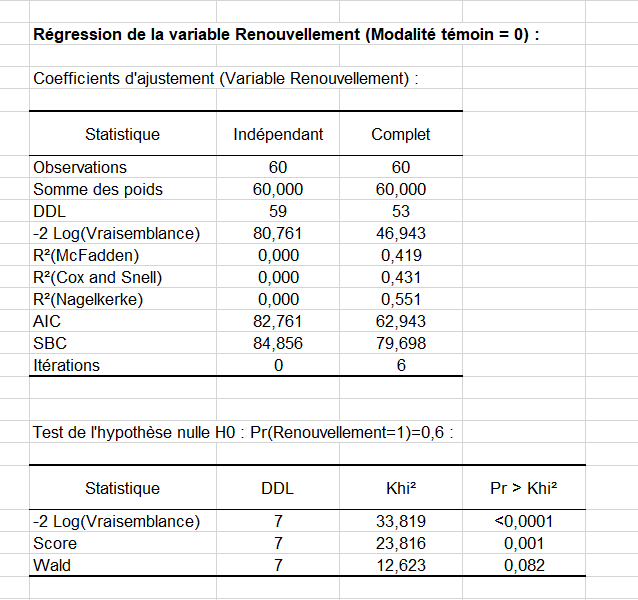
Le tableau des coefficients d’ajustement donne plusieurs indicateurs de la qualité du modèle (ou qualité de l'ajustement). Ces résultats sont équivalents au R² de la régression linéaire et au tableau d'analyse de la variance ANOVA. La valeur la plus importante est le Khi² associé au Log ratio (L.R.). C'est l'équivalent du test F de Fisher du modèle linéaire : nous essayons d'évaluer si les variables apportent une quantité d'information significative pour expliquer la variabilité de la variable réponse. Dans notre cas, comme la probabilité est inférieure à 0.0001, nous pouvons conclure que les variables apportent une quantité significative d'information.
Ensuite le tableau de l’analyse de Type II donne les premiers détails sur le modèle. Il est utile pour évaluer la contribution des variables à l’explication de la variable réponse.
D’après la probabilité associée aux tests du Khi², nous pouvons voir que la variable qui influence le plus le renouvellement est le nombre de pages vues la semaine précédente (p = 0.012).
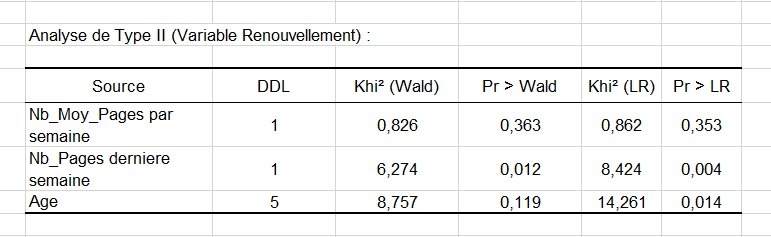
Etant donné que la variable Age est qualitative ici (car divisée en groupes), nous pouvons déterminer si chaque modalité influence la variable réponse. Il apparait que l'appartenance à la classe d'âge 40-49 a un rôle fortement négatif (-2.983). Ce dernier point devra être approfondi par les responsables marketing et éditoriaux, afin d'étudier le pourquoi de cette situation. Les autres classes d’âges ne sont pas significatives.
Par la suite, vous pouvez visualiser le tableau des Prédictions et résidus. Nous voyons notamment que pour la septième observation le lecteur indique ne pas vouloir renouveler son abonnement alors que le modèle prédit un renouvellement de son abonnement. En effet nous pouvons voir que la probabilité de renouveler est estimée à 0.757 tandis que la probabilité de ne pas renouveler est estimée à 0.243.

La colonne Changement significatif nous indique que le changement de valeur entre la modalité prédite et celle du jeu de données est significatif. La deuxième colonne Significatif indique quant à elle, quelle que soit la modalité retenue, si la probabilité pour cette modalité est significativement supérieure ou non à celles des autres modalités. Dans le cas de la septième observation, nous pouvons voir que le changement est significatif et la probabilité de renouveler (0.757) est supérieure à celle de ne pas renouveler (0.243).
A noter que ces deux colonnes apparaissent si l’option Analyse de significativité a été cochée dans l’onglet « Sorties » de la boite de dialogue.
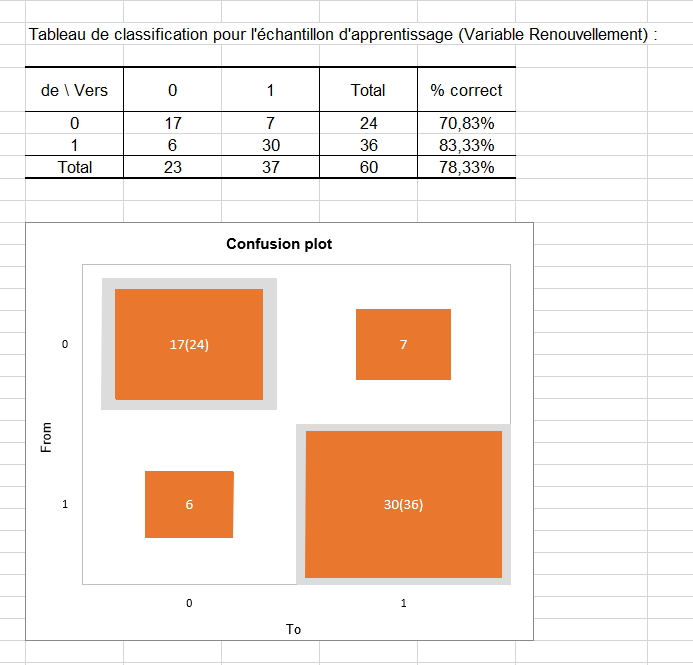
Le tableau de classification pour l'échantillon d'apprentissage (parfois appelée matrice de confusion) est ensuite affiché dans le rapport. Ce tableau permet de visualiser le pourcentage d'observations bien classées pour chaque modalité (vrais positifs et vrais négatifs). Par exemple, nous pouvons voir que les observations de la modalité 0 (pas de renouvellement) ont bien été classées à 70.83% alors que les observations de la modalité 1 (renouvellement) ont bien été classées à 83.33%.

Le confusion plot permet de visualiser synthétiquement ce tableau. Les carrés en gris sur la diagonale représentent les effectifs observés pour chaque modalité. Les carrés orange représentent quant à eux, les effectifs prédits pour chaque modalité. Ainsi, nous pouvons voir que les surfaces des carrés se superposent quasiment intégralement pour les deux modalités (17 observations bien prédites sur 24 observations observées pour la modalité 0 et 30 observations bien prédites sur 36 observations observées pour la modalité 1).
Enfin, les deux derniers tableaux prennent en compte l’incertitude. Nous pouvons voir que quasiment la totalité des valeurs prédites par le modèle pour la modalité 0 peuvent être considérées comme incertaines (95.83%), alors que dans le cas de la modalité 1 les valeurs prédites par le modèle sont beaucoup moins incertaines puisque le pourcentage d’incertitude est estimé à 33.33%.
Le dernier tableau nous indique que 40% des observations ont été bien classées (vrais positifs), 58.33% ont un classement incertain et seulement 1.67% ont été mal classées (faux positifs et faux négatifs cumulés). L’indice GCI (Goodness of Classification Index), quant à lui, est de 67.50%, ce qui signifie que la qualité prédictive de ce modèle de classification est satisfaisante.

Pour terminer, la courbe ROC est affichée. Cette courbe permet de déterminer si le point de séparation 0.5 est finalement le plus adapté à nos données, et permet aussi de définir des priorités de bonne prédiction d’une modalité de la variable réponse ou de l’autre si besoin. Plus la valeur choisie sera basse, plus le modèle aura tendance à prédire « 1 », et inversement. Pour plus d’information sur la courbe ROC, vous pouvez vous consulter notre tutoriel.


Cet article vous a t-il été utile ?
- Oui
- Non