Tests d'aptitude interlaboratoires dans Excel
Ce tutoriel explique comment mettre en place et interpréter un test d'aptitude interlaboratoires dans Excel en utilisant le logiciel XLSTAT.
Qu'est-ce que les tests d'aptitude interlaboratoires ?
Les essais d'aptitude, aussi appelés comparaisons interlaboratoires, permettent de comparer les résultats d'essais obtenus par différents laboratoires. Ce processus vise à évaluer les performances des laboratoires et constitue un élément essentiel de contrôle de qualité pour tout laboratoire d'essai.
XLSTAT permet une analyse hautement automatisée des données de laboratoires et peut produire une série de statistiques classiques et robustes qui peuvent ensuite être utilisées pour interpréter les résultats et définir dans quelle mesure les normes sont respectées.
Cet outil est basé sur la norme ISO-13528. Il a été développé à l'aide de l'édition 2015 de la norme. Certaines erreurs ayant été détectées dans la version 2015 du document XLSTAT permet également aux utilisateurs d'effectuer l'analyse en incluant les erreurs.
Données pour mettre en place un test d'aptitude interlaboratoires
Les données sont des résultats obtenus lors d’un test d'aptitude effectué par 29 laboratoires qui ont mesuré la quantité d'anticorps dans deux allergènes similaires. Les données sont des nombres d'unités en milliers par litre d'échantillon, où une unité est définie par la concentration d'un matériau de référence international. Les lignes représentent les laboratoires et les colonnes les concentrations d'anticorps.
Configurer un test d'aptitude interlaboratoires avec XLSTAT
Une fois XLSTAT lancé, allez dans le menu Analyse de données de laboratoire de XLSTAT et choisissez la fonctionnalité Tests d’aptitude interlaboratoires.

La boîte de dialogue Tests d’aptitude interlaboratoires s’ouvre.
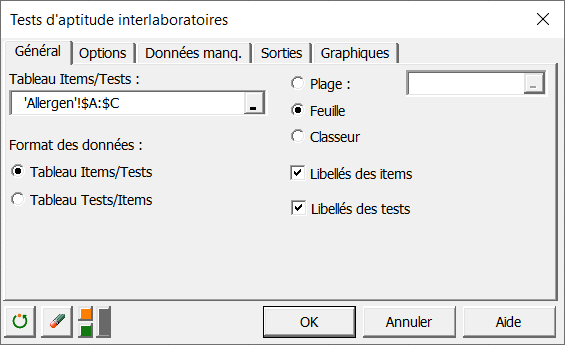
Dans l'onglet Général, sélectionnez l'ensemble de mesures et choisissez le format Tableau Item/Tests puisque les lignes correspondent aux laboratoires (items) et les colonnes aux mesures (tests).
Dans l'onglet Options, choisissez si vous voulez utiliser la moyenne ou la médiane comme estimateur de localisation. Si vous voulez que XLSTAT ne prenne pas en compte les erreurs dans le calcul de la statistique Qn, désactivez l'option "Erreurs ISO-13528-2015".
Sélectionnez la statistique d'échelle (intervalle ou écart type) à estimer par l'estimateur robuste de l'algorithme S. Pour l'algorithme A, vous avez la possibilité d'utiliser l'intervalle, l'écart type en utilisant l'approche de Grubbs pour éliminer les valeurs aberrantes, le nIQR, Qn ou Q comme statistique d'échelle.
Le choix de l'algorithme est généralement effectué par la personne qui met en place le test d'aptitude et dépend de divers facteurs tels que le nombre de participants/laboratoires et le volume de valeurs aberrantes dans les mesures.
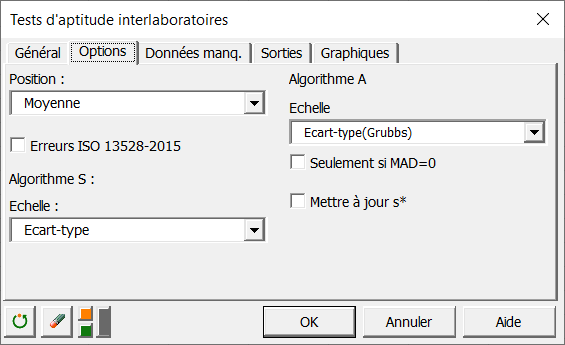
Si la MAD (Écart absolu médian) est nulle, vous pouvez la remplacer par la médiane des différences absolues avec la moyenne. Il est également possible de mettre à jour l'estimation robuste s* (échelle) à chaque itération de l'algorithme.
Résultats d’un test d'aptitude interlaboratoires avec XLSTAT
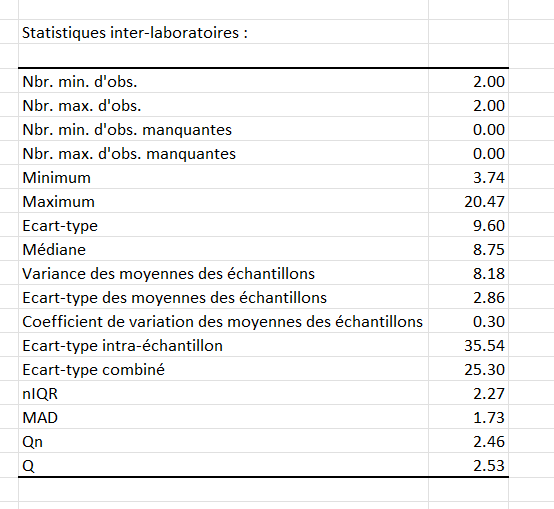
Dans cet exemple, il y a plusieurs laboratoires et deux tests (mesures). XLSTAT affiche tout d’abord une liste de statistiques pour chacun d'entre eux, y compris des statistiques robustes telles que la médiane, l'écart absolu médian échelonné (MAD), et l'IQR normalisé (nIQR). Ces dernières sont des estimateurs simples.
Les méthodes Qn et Q d'estimation de l'écart-type sont particulièrement utiles dans les situations où une grande proportion (>20 %) des résultats peut être incohérente, ou lorsque les données ne peuvent pas être examinées de manière fiable par des experts.
Les statistiques récapitulatives sont ensuite calculées pour l'ensemble des items.
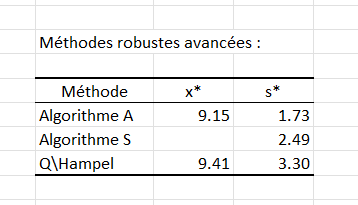
Le tableau suivant fournit les estimations des algorithmes avancés décrits dans la norme ISO-13528 (Algorithme A, Algorithme S, Q/Hampel), certains d'entre eux étant très résistants aux valeurs aberrantes. L'algorithme A et la méthode Q/Hampel sont utilisés pour obtenir des estimateurs robustes de localisation et d’échelle. L'algorithme S est utilisé pour estimer le paramètre d'échelle à partir d’écarts types ou d’amplitudes.
L'algorithme A est un estimateur alternatif de la moyenne et de l'écart-type pour les données quasi-normales et est le plus utile lorsque la proportion attendue de valeurs aberrantes est inférieure à 20 %. Plus de détails sur les avantages de chaque méthode sont fournis dans le document de la norme ISO-13528.
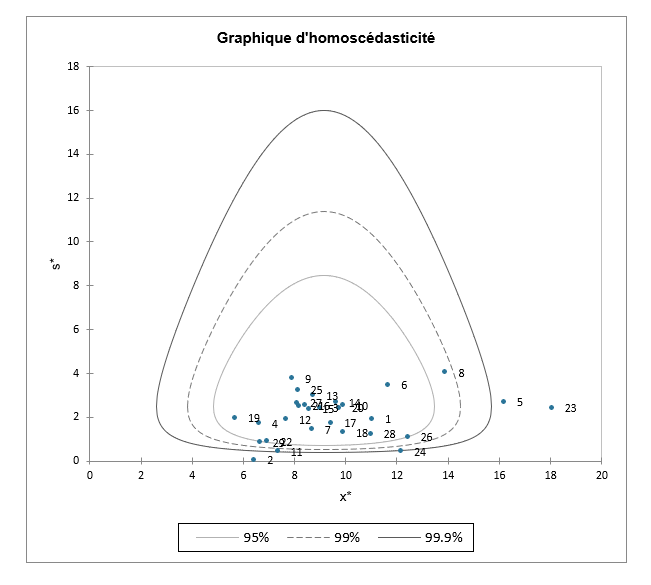
Un graphique d'homoscédasticité est affiché pour comparer les estimations de localisation et d'échelle des différents laboratoires. Plus l'écart sur l'axe vertical est important, moins l'hypothèse d'une variance constante entre les laboratoires est valable. Des intervalles de confiance (90 %, 95 %, 99 %) sont affichés pour identifier les laboratoires qui présentent des valeurs potentiellement aberrantes, comme les laboratoires 23, 5 et 8.
Cet article vous a t-il été utile ?
- Oui
- Non