Generar distribuciones en modelo de simulación por copiado
Este tutorial le mostrará cómo configurar un modelo de simulación y generar muchas distribuciones en Excel utilizando el software estadístico XLSTAT.
¿Qué son los modelos de Simulación?
Los modelos de simulación permiten obtener información de variables (por ejemplo, la media, la mediana o los intervalos de confianza) que no tienen un valor exacto, pero de las que, o bien conocemos, o bien suponemos una distribución. Si algunas variables “resultado” dependen de estas variables “distribuidas” por medio de fórmulas conocidas o supuestas, entonces las variables “resultado” también tendrán una distribución. Los modelos de simulación permiten definir las distribuciones, y luego obtener, a través de simulaciones, una distribución empírica de las variables de entrada y de salida, así como los estadísticos correspondientes.
Los modelos de simulación se utilizan en muchas áreas como las finanzas y los seguros, la medicina, la prospección de petróleo y gas, la contabilidad, o la predicción de ventas.
Cuatro elementos están involucrados en la construcción de un modelo de simulación:
1. Las distribuciones se asocian a variables aleatorias. XLSTAT ofrece una selección de más de 30 distribuciones para describir la incertidumbre en los valores que una variable puede tomar. Por ejemplo, se puede elegir una distribución triangular si tiene una cantidad por la que usted sabe que puede variar entre dos límites, pero con un valor que es más probable (un modo). En cada iteración del cálculo del modelo de simulación, se realiza un sorteo para cada distribución que se ha definido.
2. Las variables Escenario permiten incluir en el modelo de simulación de una cantidad que se fija en el modelo, excepto durante el análisis Tornado, en los que puede variar entre dos límites.
3. Las variables de Resultado corresponden a las salidas del modelo. Dependen directa o indirectamente, a través de una o más fórmulas de Excel, de las variables aleatorias a las que se han asociado las distribuciones y, en su caso, de las variables de escenario. El objetivo de calcular el modelo de simulación es obtener la distribución de las variables de resultados.
4. Los Estadísticos permiten realizar un seguimiento de un estadístico dado para una variable de resultado. Por ejemplo, podríamos querer controlar la desviación típica de una variable de resultado.
Un modelo correcto debería comprender al menos una distribución y una variable de resultado. Los modelos pueden contener cualquier número de los cuatro elementos de la lista. Un modelo puede limitarse a una sola hoja de Excel, o puede utilizar una carpeta completa de Excel.
En este tutorial se crea un modelo de simulación para simular el pago de intereses de un préstamo reembolsable a 5 años; se utiliza el tipo de interés del primer año para calcular el valor del beneficio neto. Durante este tutorial se introduce la copia de celdas de distribución utilizando la función normal de copiar y pegar de Excel.
Datos para la generación de muchas distribuciones en un modelo de simulación de manera eficiente
Nuestro modelo de simulación se ocupa de los pagos de interés de un préstamo reembolsable. El interés se calcula durante 5 años. Al final se calcula el valor de ganancia neta en el momento inicial utilizando la función de Excel NPV, así como el tipo de interés del primer año y los pagos de interés durante los 5 años. El tipo de interés se supone distribuido en partes iguales entre el 3.5% y el 5.5%. El capital del préstamo reembolsable es de 10.000 euros.
Se comienza con un modelo estático que utiliza un tipo de interés promedio del 4.5%. El valor de ganancia neta se calcula a 1975 euros en ese caso.

Este modelo se puede encontrar en la hoja “Model”.

Generación de muchas distribuciones en un modelo de simulación de manera eficiente mediante copia
A continuación utilizamos referencias relativas para copiar las distribuciones correctamente. Por favor, verifique, en las Opciones de Sim, que la opción de Referencia relativa está activada antes de crear las variables de distribución. Esto permite que las acciones de copiar / pegar cambien la referencia de forma automática.
Creación de la primera distribución
Seleccione la primera variable de distribución en B6, “interest rate” para el año 2008, para convertirla en la celda activa.
Una vez que se activa XLSTAT, seleccione el comando XLSTAT / Simulaciones de Monte Carlo / Definir una distribución, o bien haga clic en el botón correspondiente de la barra de herramientas Sim (ver siguiente captura de pantalla).

Aparece el cuadro de diálogo. Elija la celda de Excel con el nombre “2008” como nombre. Esto se integra como una referencia relativa (formato A1) en la fórmula.
Elija una distribución uniforme con a = 0.035 y b = 0.055.

Una vez haya hecho clic en OK, se inserta en la celda activa la llamada a la función correspondiente a XLSTAT_SimDist.
Creación de distribución mediante copia
Es posible introducir las otras cuatro distribuciones copiando y pegando la celda que hemos generado en las cuatro celdas a la derecha de esta primera celda. Tenemos además la posibilidad, como sucede con cualquier fórmula de Excel, de seleccionar la celda B6 que acabamos de generar, trasladarnos con el puntero del ratón a la esquina inferior izquierda, donde se muestra el cursor en forma de cruz de color negro, presionar y mantener presionado el botón izquierdo del ratón, y mover el ratón hasta la celda F6. De esta manera se han definido asimismo las 5 celdas. El nombre de las distribuciones será “2008, ..., 2012”.
![]()
Elija la celda de resultados B9, que contiene la fórmula = NPV(B6,B7,C7,D7,E7,F7) como celda activa. Ahora se definirá la variable de resultado. Seleccione el comando XLSTAT / Simulaciones de Monte Carlo / Definir un resultado, o bien haga clic en el botón correspondiente de la barra de herramientas Sim.
Aparecerá el cuadro de diálogo Definir un resultado. A continuación, seleccione los datos en la hoja de cálculo de Excel. Elija la celda de Excel identificada con el nombre de “NPV”.
Una vez haya hecho clic en OK, se inserta en la celda activa la correspondiente llamada a la función de XLSTAT_SimRes.
Esto se puede encontrar en hoja de Excel “Model”.
Ejecución de la simulación
Para iniciar la ejecución de la simulación, seleccione el comando XLSTAT / Simulaciones de Monte Carlo / Iniciar los cálculos, o bien haga clic en el botón correspondiente de la barra de herramientas Sim.
Aparece el cuadro de diálogo de inicio de los cálculos. Fije el número de simulaciones en 1000.
En la pestaña Gráficos - Sensibilidad, introduzca los parámetros de los análisis Tornado y Araña. Seleccione el valor de la celda estándar como valor por defecto. Elija 10 puntos de datos en el intervalo de -10% a +10% de la desviación del valor:

Los cálculos empiezan una vez haya hecho clic en OK.
Interpretación de los resultados de la simulación
El primer resultado es un resumen de los elementos incluidos en el modelo. Se muestran detalles en las variables de distribución y en la variable de resultado.

Las siguientes tablas muestran estadísticos descriptivos, histogramas y cuantiles para cada variable de distribución.

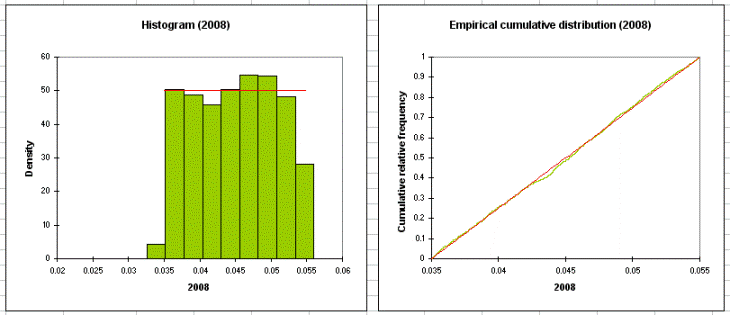
Las siguientes tablas muestran los detalles de las variables de resultado (estadísticos descriptivos, histogramas y cuantiles). A continuación, se muestran los resultados del análisis de sensibilidad. Estos resultados dependen de las iteraciones de las simulaciones.

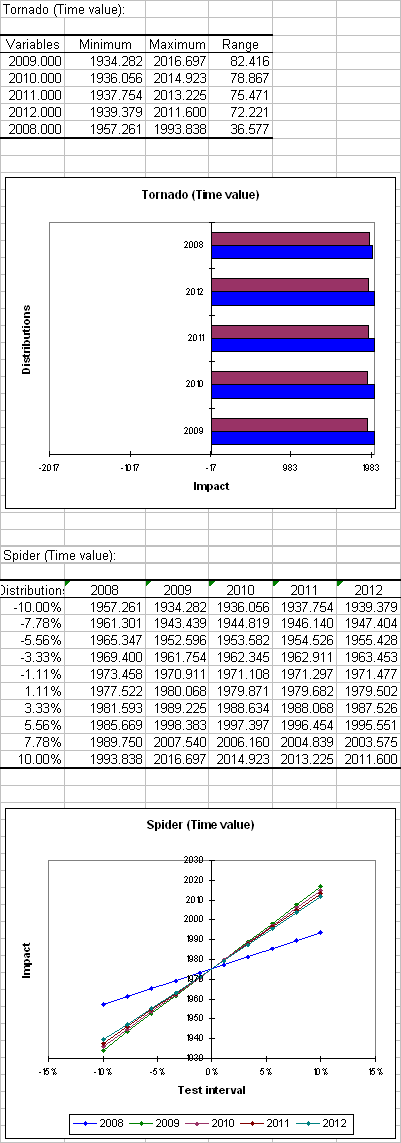
La siguiente sección contiene el análisis Tornado. Los análisis Tornado y Araña no se basan en las iteraciones de la simulación, sino en un análisis punto por punto de todas las variables de entrada (variables aleatorias con distribuciones y variables de escenario).
Durante el análisis Tornado, para cada variable de resultado, se estudian una por una cada variable aleatoria de entrada y cada variable de escenario. Hacemos que su valor varíe entre dos límites, y registramos el valor de la variable de resultado con el fin de saber cómo cada variable aleatoria y de escenario impacta en las variables de resultado. Para una variable aleatoria, los valores explorados pueden estar en torno a la mediana o en torno al valor por defecto de la celda, con límites definidos por los percentiles o la desviación. Para una variable de escenario, el análisis se lleva a cabo entre dos límites especificados en la definición de las variables. El número de puntos es una opción que puede ser modificada por el usuario antes de ejecutar el modelo de simulación.
El análisis de Araña no sólo muestra el cambio máximo y el mínimo de la variable de resultado, sino también el valor de la variable de resultado para cada punto de datos de las variables aleatoria y de escenario. Esto resulta útil para comprobar si la dependencia entre las variables de distribución y variables de resultado es o no monotónica.
En la primera tabla se muestra, para cada variable de distribución, el cambio mínimo y máximo, así como el rango correspondiente. En este caso todos los tipos de interés son más o menos lo mismo. En el análisis de Araña en la siguiente sección vemos que la tasa de interés del primer año tiene un impacto menor que las otras tasas de interés, debido a que en la fórmula del NPV se utiliza también la tasa de interés del primer año y, por tanto, las variaciones de este tipo interés no tienen mucha influencia en el NPV.
¿Ha sido útil este artículo?
- Sí
- No