Agglomerative Clusterverfahren in Excel - Anleitung
Dieses Tutorium wird Ihnen helfen, ein agglomeratives hierarchisches Clustering (AHC) in Excel mithilfe der Software XLSTAT einzurichten und zu interpretieren.
Sie sind nicht sicher, ob dies das richtige Clustering-Tool ist, das Sie benötigen? Weitere Hinweise finden Sie hier.
Datensatz für die Durchführung eines agglomerativen hierarchischen Clustering in XLSTAT
Die Daten stammen vom US Census Bureau. Sie entsprechen einer Erhebung von demographischen Merkmalen in 51 Staaten der vereinigten Staaten in 2000 und 2001. Der Ausgangsdatensatz wurde in Anteilen pro 1000 Einwohner transformiert, wobei die Daten des Jahres 2001 als Schwerpunkt der analyse benutzt wurden.
Ziel dieses Tutorials
Das Ziel ist es, homogene Gruppen von Staaten zu finden basierend auf den vorliegenden demografischen Daten.
Einrichten eines agglomerativen hierarchischen Clustering
-
Nach dem Öffnen von XLSTAT, wählen Sie den Befehl XLSTAT/Analyse der Daten/Agglomerative Hierarchisches Clustering.
-
Nach dem Klicken des Buttons erscheint das entsprechende Dialogfenster des Hierarchischen Clusterings. Sie können nun die Daten im Excel-Blatt auswählen.
Hinweis: Es gibt mehrere Arten die Daten in den XLSTAT Dialogfenstern auszuwählen (siehe auch das Tutoriel Selecting data in Excel with XLSTAT zu diesem Thema).
-
In diesem Beispiel beginnen die Daten in der ersten Zeile, daher ist es schneller und einfacher, die Spaltenauswahl zu verwenden. Dies erklärt, warum die Buchstaben, die den Spalten entsprechen, in den Auswahlfeldern angezeigt werden.
-
Die Variable "Gesamtbevölkerung" wurde nicht ausgewählt, da wir uns hauptsächlich für die demografische Dynamik interessieren. Die letzte Spalte wurde nicht ausgewählt, da sie vollständig mit der vorhergehenden Spalte korreliert ist.
-
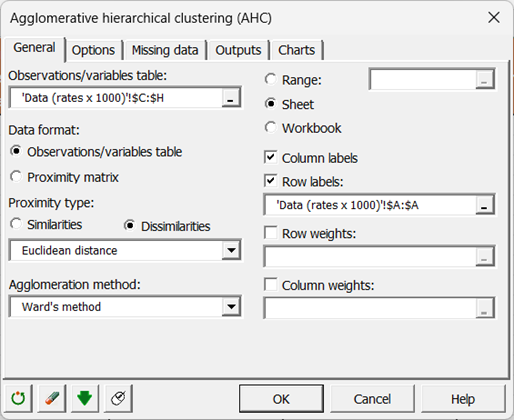
Da der Name jeder Variablen oben in der Tabelle vorhanden ist, müssen wir das Kontrollkästchen Variablenbezeichnungen aktivieren. Außerdem sind Zeilenbeschriftungen ausgewählt.
-
Standardmäßig verwenden wir den euklidischen Abstand und die Ward-Methode als Agglomerationsmethode.
-
Im Options-Tab wurden die Optionen Zentrieren/Reduzieren ausgewählt, um zu vermeiden, dass die Clustererstellung durch Skalierungseffekte beeinflusst wird.
-
Wir haben die Trunkierungsoption aktiviert, und um eine willkürliche Anzahl von Clustern zu vermeiden, haben wir den Hartigan-Index verwendet. Dieser Index ermöglicht es Ihnen, die Qualität mehrerer Cluster gemäß einer festgelegten Clusteranzahl zu vergleichen.
-
Wir möchten eine Clusteranzahl zwischen 2 und 5. Der Hartigan-Index wird automatisch die geeignete Anzahl von Clustern in diesem Bereich definieren.
-
Die Berechnungen beginnen, sobald Sie auf OK geklickt haben.
Interpretieren der Ergebnisse eines agglomerativen hierarchischen Clustering
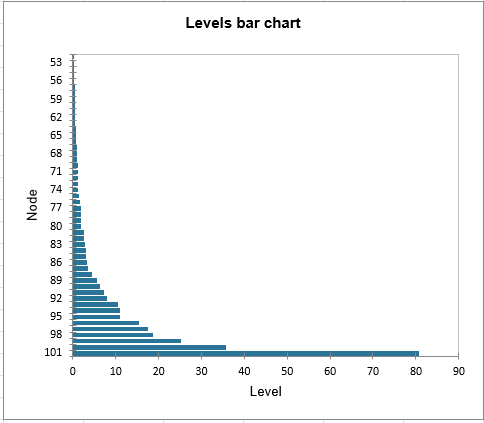
Das erste Ergebnis, das betrachtet werden sollte, ist das Balkendiagramm der Ebenen. Die Form verrät viel über die Struktur der Daten. Wenn der Anstieg des Dissimilaritätsniveaus stark ist, haben wir ein Niveau erreicht, bei dem wir Gruppen zusammenfassen, die bereits homogen sind, aber untereinander heterogen.
Das untenstehende Diagramm ist das Dendrogramm. Es zeigt, wie der Algorithmus funktioniert, um die Beobachtungen und dann die Untergruppen von Beobachtungen zu gruppieren. Wie Sie sehen können, hat der Algorithmus alle Beobachtungen erfolgreich gruppiert.
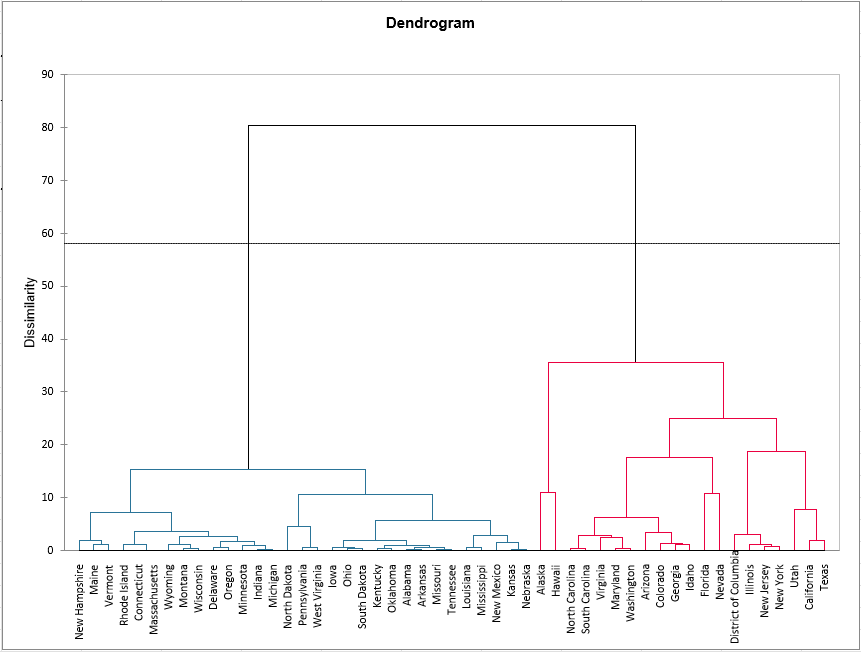
Die gestrichelte Linie stellt die automatische Trunkierung dar, die zu zwei Clustern führt. Der erste Cluster (in Blau angezeigt) ist homogener als der zweite (er ist im Dendrogramm flacher). Der Hartigan-Index definierte 2 als die geeignete Anzahl von Clustern. Die folgende Tabelle erklärt, warum wir 2 Cluster erhalten haben.
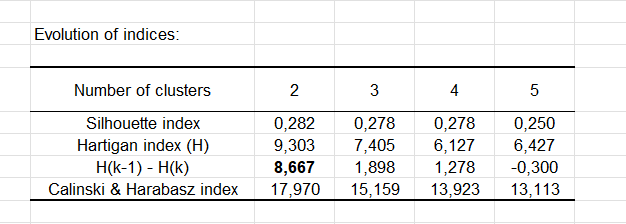
Tatsächlich informiert die Tabelle über die Entwicklung des Silhouette-Index, des Hartigan-Index und des Calinski-und-Harabasz-Index für jede Anzahl von Clustern von 2 bis 5.
In diesem Fall betrachten wir die zweite und dritte Zeile. Die zweite Zeile zeigt die Entwicklung des Hartigan-Index, während die dritte die Entwicklung der Differenz zwischen dem Index einer Clusterung mit k Clustern und einer Clusterung mit (k-1) Clustern zeigt. Die Anzahl der Cluster mit der größten Differenz (der in Fettdruck angezeigte Wert) gibt an, wie viele Cluster wir erstellen sollten, und hier sind es 2.
Die folgende Tabelle zeigt die Staaten, die in jeden Cluster klassifiziert wurden. Beim Betrachten der Varianz innerhalb der Klassen wird bestätigt, dass der erste Cluster (links im Dendrogramm) homogener ist als der zweite, da die Varianz beim zweiten Cluster (rechts) deutlich höher ist als beim ersten.
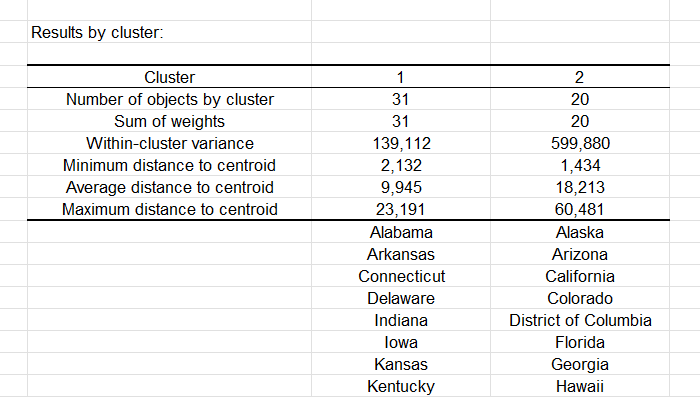
Eine Tabelle mit der Klassen-ID für jeden Staat wird im Ergebnisblatt angezeigt. Ein Beispiel wird unten gezeigt. Diese Tabelle ist nützlich, da sie mit der ursprünglichen Tabelle für weitere Analysen, wie eine ANOVA oder ein Parallelkoordinatendiagramm, zusammengeführt werden kann.
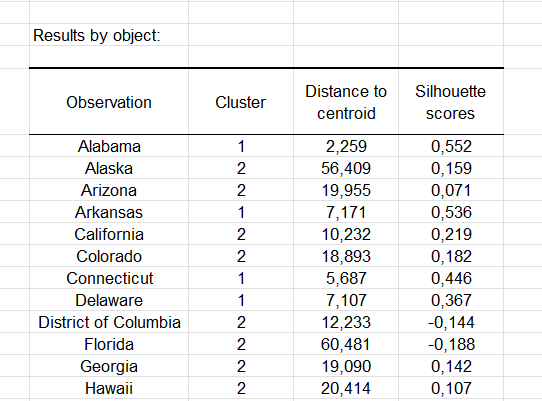
Der Silhouette-Score jeder Beobachtung kann ebenfalls angezeigt werden. Wenn der Score nahe bei 1 liegt, befindet sich die Beobachtung gut in ihrem Cluster.
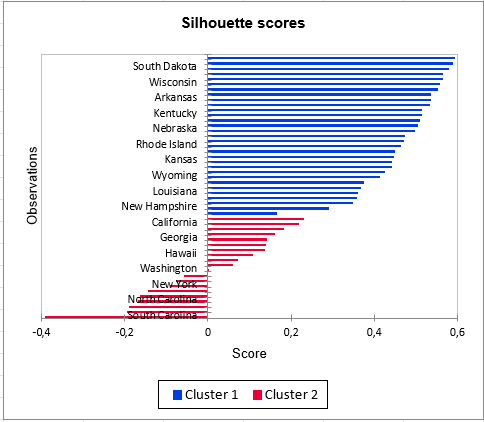
Schließlich kann dieser Score in einem Diagramm mit sortierten Beobachtungen in absteigender Reihenfolge und nach Cluster dargestellt werden, um die Qualität der erhaltenen Clusterbildung zu beurteilen. Negative Indizes für Beobachtungen in Cluster 2 beweisen erneut die geringe Homogenität dieses Clusters im Vergleich zu Cluster 1.
Schlussfolgerung zur Agglomerativen Hierarchischen Clusteranalyse
Wir haben eine Agglomerative Hierarchische Clusteranalyse durchgeführt und dank des Hartigan-Index haben wir die Staaten in zwei Cluster unterteilt. Allerdings ist ein Cluster homogener als das andere. Es ist möglich, eine bessere Clusterbildung mit zwei homogenen Clustern durch Konsolidierung mit dem k-means-Algorithmus zu erreichen. Zu diesem Zweck können Sie die Konsolidierungsoption im Tab „Optionen“ aktivieren.
Hinweis: Wenn die verwendete Distanz nicht die euklidische Distanz ist und die Agglomerationsmethode nicht die Methode von Ward ist, werden von unseren Teams Anpassungen des Hartigan- und des Calinski-Harabasz-Index vorgeschlagen, um Ihnen bei der Wahl der besten Anzahl von Klassen zu helfen.
Dieses Video zeigt, wie dieses Tutorial durchgeführt wird.

War dieser Artikel nützlich?
- Ja
- Nein