k-means Clustering in Excel Anleitung
Dieses Tutorial hilft Ihnen, ein k-means Clustering in Excel mit der XLSTAT-Software einzurichten und zu interpretieren.
Sind Sie nicht sicher, ob dies das richtige Clustering-Tool für Sie ist? Schauen Sie sich diesen Leitfaden an.
Datensatz für k-means-Clustering
Unsere Daten stammen vom US Census Bureau und beschreiben die Veränderungen in der Bevölkerung von 51 Bundesstaaten zwischen 2000 und 2001. Der ursprüngliche Datensatz wurde in Raten pro 1000 Einwohner umgewandelt, wobei die Daten für 2001 als Schwerpunkt der Analyse verwendet werden.
Ziel dieses Tutorials
Unser Ziel ist es, homogene Cluster von Bundesstaaten basierend auf den uns vorliegenden demografischen Daten zu erstellen. Dieser Datensatz wird auch im Tutorial zur Hauptkomponentenanalyse (PCA) und im Tutorial zur hierarchischen aufsteigenden Klassifikation (HAC) verwendet.
Hinweis: Wenn Sie versuchen, die unten beschriebene Analyse mit denselben Daten erneut durchzuführen, werden Sie höchstwahrscheinlich andere Ergebnisse erhalten als die unten aufgeführten, da die k-means-Methode mit zufällig ausgewählten Clustern beginnt, es sei denn, Sie fixieren den Seed der Zufallszahlen auf denselben Wert wie hier (4414218). Um den Seed zu fixieren, gehen Sie zu den XLSTAT-Optionen, Registerkarte Erweitert, und aktivieren Sie die Option Seed fixieren.
Einrichten eines k-means-Clustering in XLSTAT
-
Sobald XLSTAT geöffnet ist, klicken Sie auf Daten analysieren / k-means-Clustering.
-
Das k-means-Clustering-Dialogfeld erscheint.
-
Wählen Sie die Daten im Excel-Blatt aus. In diesem Beispiel beginnen die Daten in der ersten Zeile, daher ist es schneller und einfacher, den Spaltenauswahlmodus zu verwenden. Dies erklärt, warum die Buchstaben, die den Spalten entsprechen, in den Auswahlfeldern angezeigt werden.
-
Die Variable GESAMTBEVÖLKERUNG wurde nicht ausgewählt, da wir uns hauptsächlich für die demografische Dynamik interessieren. Die letzte Spalte (> 65 BEV. SCHÄTZ.) wurde nicht ausgewählt, da sie vollständig mit der vorhergehenden Spalte korreliert ist.
-
Da der Name jeder Variablen oben in der Tabelle vorhanden ist, müssen wir das Kontrollkästchen Variablenbeschriftungen aktivieren.
-
Das ausgewählte Kriterium ist der Determinant(W), da er Ihnen ermöglicht, die Skaleneffekte der Variablen zu eliminieren.
-
Der euklidische Abstand wird als Dissimilaritätsindex gewählt, da er der klassischste ist, der für k-means-Clustering verwendet wird.
-
Wir haben die Anzahl der zu erstellenden Cluster auf 4 festgelegt.
-
Schließlich werden die Zeilenbeschriftungen ausgewählt (SPALTE STAAT), da der Name des Staates für jede Beobachtung angegeben ist.

-
Im Register Optionen haben wir die Anzahl der Wiederholungen auf 10 erhöht, um die Qualität und Stabilität der Ergebnisse zu verbessern.
-
Schließlich können wir im Register Ausgaben auswählen, ob eine oder mehrere Ausgabetabellen angezeigt werden sollen.
Interpreting a k-means clustering
Nach den grundlegenden deskriptiven Statistiken der ausgewählten Variablen und der Optimierungszusammenfassung wird als erstes das Trägheitszerlegungstabelle angezeigt.
Die Trägheitszerlegungstabelle für die beste Lösung unter den Wiederholungen wird angezeigt. (Hinweis: Gesamte Trägheit = Trägheit zwischen den Klassen + Trägheit innerhalb der Klasse).

Nach einer Reihe von Tabellen, die die Klassen-Zentroiden, die Entfernung zwischen den Klassen-Zentroiden, die zentralen Objekte (hier, der Staat, der dem Klassen-Zentroid am nächsten liegt) umfassen, zeigt eine Tabelle die Staaten, die in jeden Cluster klassifiziert wurden.
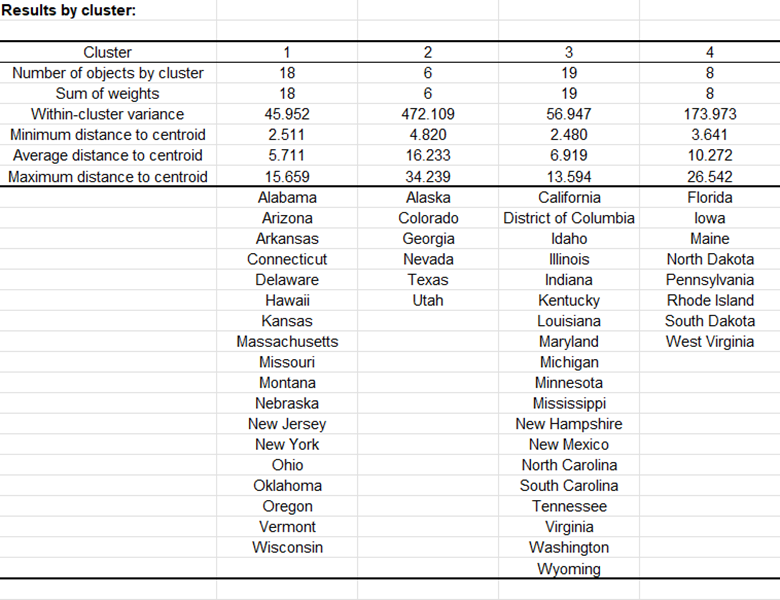
Dann wird eine Tabelle mit der Gruppen-ID für jeden Staat angezeigt. Ein Beispiel wird unten gezeigt. Die Cluster-IDs können mit der ursprünglichen Tabelle zusammengeführt werden, um weitere Analysen (z.B. Diskriminanzanalyse) durchzuführen.
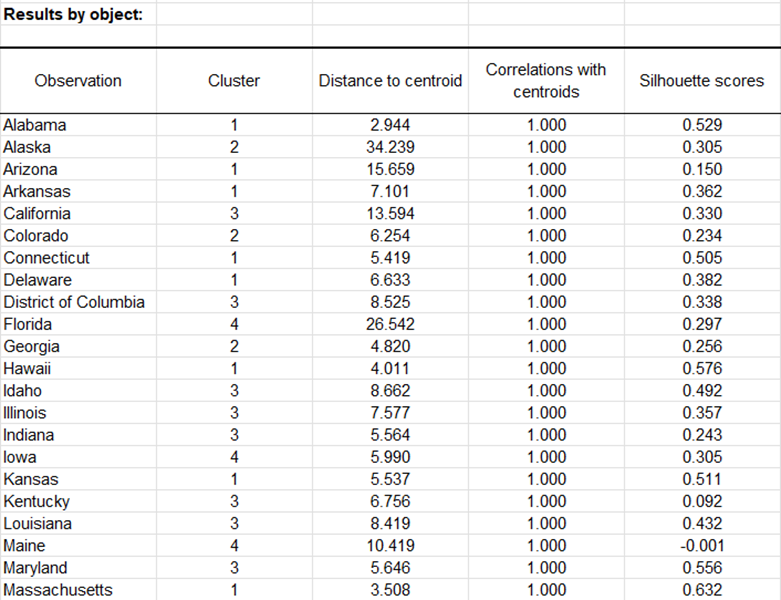
Die Optionen Korrelationskoeffizienten mit Zentroiden und Silhouette-Werte sind aktiviert, dann werden die zugehörigen Spalten in derselben Tabelle angezeigt:
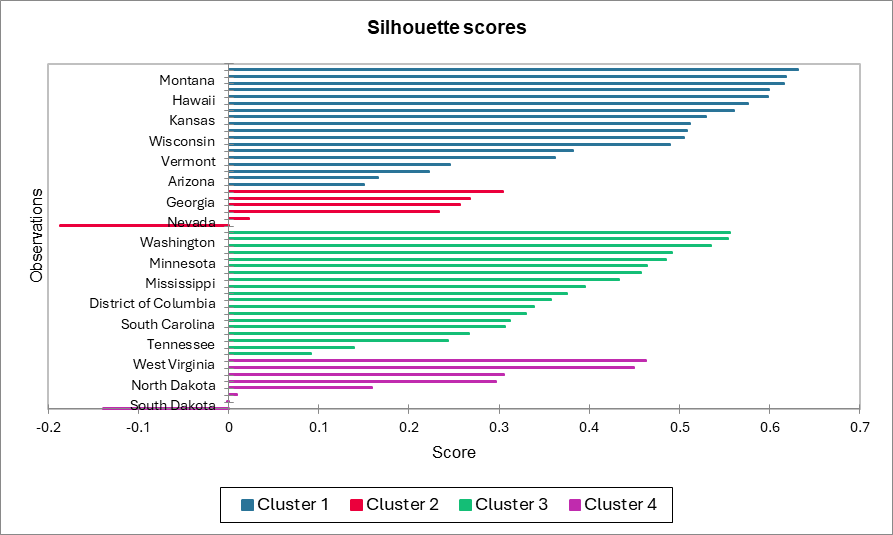
Ein Diagramm, das die Silhouette-Werte darstellt, ermöglicht es Ihnen, die Qualität der Clusterbildung visuell zu untersuchen. Wenn der Wert nahe bei 1 liegt, befindet sich die Beobachtung gut in ihrer Klasse. Im Gegenteil, wenn der Wert nahe bei -1 liegt, wurde die Beobachtung der falschen Klasse zugeordnet.
Durchschnittliche Silhouette-Werte nach Klasse ermöglichen es Ihnen, Klassen zu vergleichen und herauszufinden, welche Klasse gemäß diesem Wert die gleichmäßigste ist.
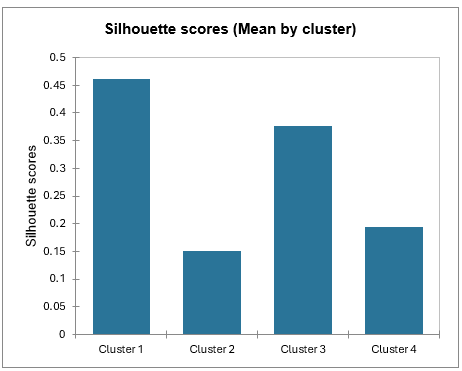
Klasse 1 hat die höchsten Silhouette-Werte. Klasse 2 hingegen hat einen Wert nahe bei 0, was bedeutet, dass 4 nicht die beste Anzahl von Klassen für diese Daten ist. Im Tutorial über Agglomerative Hierarchische Clusteranalyse (AHC) sehen wir, dass die Staaten besser in drei Gruppen aufgeteilt wären.
War dieser Artikel nützlich?
- Ja
- Nein