Sentiment analysis in Excel
Documents to categorize using the sentiment analysis with XLSTAT
This tutorial is based on a dataset containing the lyrics of 94 American singer Taylor Swift songs. The dataset is extracted from the data science platform, Kaggle and might be accessed at this address.
Setting up the sentiment analysis feature in XLSTAT
-
Open XLSTAT.
-
Select the XLSTAT/ Text Mining / Sentiment analysis. The dialog box pops up.
-
In the XLSTAT interface, select the term frequencies from the document-term matrix obtained with the feature extraction feature.
-
Select the Bing sentiment dictionary, which allows you to use a binary dictionary. Each term will then be associated with a positive or negative sentiment.
-
Select song titles as document labels.
-
Click on OK.
Interpret the results of the sentiment analysis
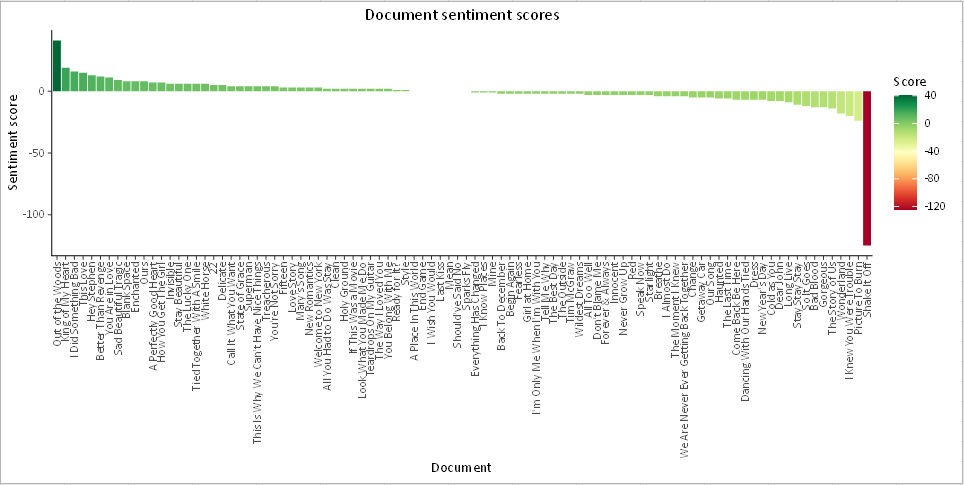
The document score is the sum of the products of the term score multiplied by the term frequency. The more positive a document is, the higher its sentiment score. In our case, the song with the most positive intent is "Out of the woods" while the most negative is "Shake it off".
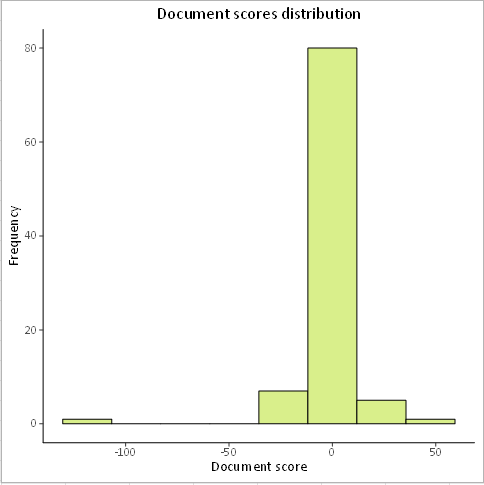
 The distribution of the scores of the documents allows us to know here that the majority of the songs have a score close to zero, thus neutral.
The distribution of the scores of the documents allows us to know here that the majority of the songs have a score close to zero, thus neutral.
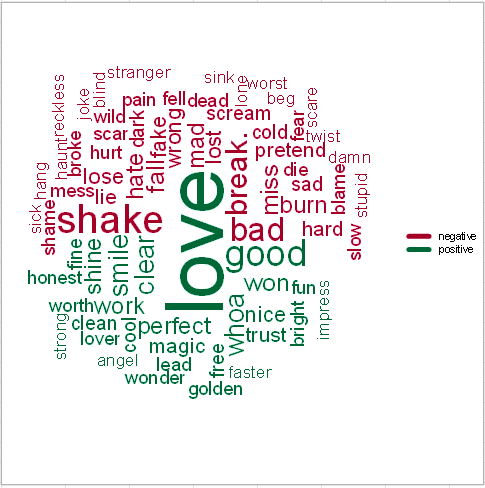
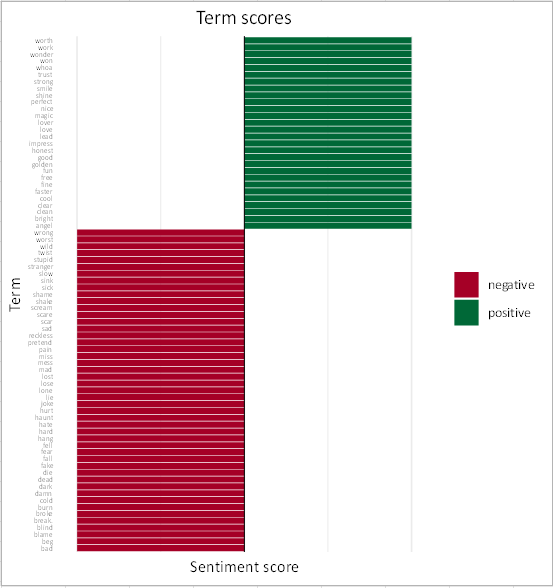
 The sentiment-based word cloud is interpreted as a classic word cloud but here the words are colored according to their sentiment. It shows that "love" is the most present positive word in the 94 songs of Taylor Swift, while "shake" and "bad" seem to be the most present negative words. This explains why the song "Shake it off" is categorized as negative.
The sentiment-based word cloud is interpreted as a classic word cloud but here the words are colored according to their sentiment. It shows that "love" is the most present positive word in the 94 songs of Taylor Swift, while "shake" and "bad" seem to be the most present negative words. This explains why the song "Shake it off" is categorized as negative.
Tips: The score of the term "shake" can be decreased or neutralized so that it does not influence the score of the song "Shake it off". To do so, you must activate the custom scores option.
The last chart gives a view of the scores of each term, it allows seeing the sentimental category of each term.
Was this article useful?
- Yes
- No