Forêt aléatoire de classification dans Excel
Ce tutoriel vous aidera à mettre en place et entraîner une forêt aléatoire pour réaliser une classification dans Excel en utilisant le logiciel de statistiques XLSTAT.
Jeu de données pour générer une Forêt aléatoire de classification
Le jeu de données est extrait de la compétition de Machine Learning intitulé Titanic: Machine Learning from Disaster sur Kaggle, la fameuse plateforme de data science. Il fait référence au naufrage du fameux paquebot le Titanic en 1912. Au cours de cette tragédie, plus de 1500 des 2224 passagers trouvèrent la mort en partie à cause d'un nombre insuffisant de canots de survie.
Le jeu de données en question est constitué d'une liste de 1309 passagers et des informations suivantes :
-
Survived : le passager a survécu (0 = Non; 1 = Oui)
-
Pclass : Classe voyage (1 = 1ère; 2 = 2nde; 3 = 3ème)
-
Name : Nom
-
Sex : Genre (homme ; femme)
-
Age : Age
-
Sibs : Nombre de frères et soeurs / épouses à bord
-
Parch : Nombre de parents / enfants à bord
-
Fare : Tarif pour le passager
-
Cabin : Cabine
-
Embarked : Port d'embarquement (C = Cherbourg ; Q = Queenstown; S = Southampton)
L'objectif de ce tutoriel est d'apprendre à mettre en place et entrainer une Forêt aléatoire de classification sur le jeu de données Titanic.
Paramétrer une Forêt aléatoire de classification dans XLSTAT
Une fois XLSTAT lancé, cliquez sur Machine Learning / Forêt aléatoire de classification et de régression comme indiqué ci-dessous :
Une fois que vous avez cliqué sur le bouton, la boîte de dialogue apparait.
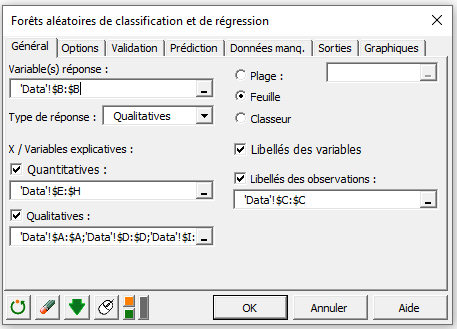
Sélectionnez la colonne B (Pclass) dans le champ Variable réponse et choisissez le type de réponse Qualitative. Il faut également sélectionner des variables explicatives Quantitatives et Qualitatives en activant les deux options comme illustré au-dessus.
Comme le nom de chaque variable est présent au début du fichier, assurez-vous que la case Libellés des variables est cochée. Ayant à disposition le nom de chaque passager présent, activer l’option Libellés des observations et sélectionnez la colonne C (Name).
Dans l'onglet Options, vous pouvez ajuster plusieurs paramètres ayant une incidence sur la construction des arbres comme indiqué ci-dessous.
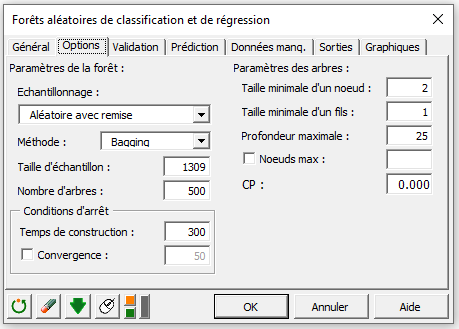
Les données comprennent des valeurs manquantes, nous décidons donc de supprimer ces dernières de notre base d’apprentissage dans l’onglet Données manquantes.
Dans l'onglet sorties, sélectionnez les sorties voulues en cochant les cases concernées comme indiqué ci-dessous :
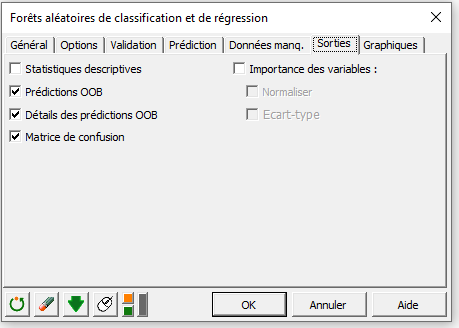
Dans l’onglet Graphiques, activez l’option Evolution de l’erreur OOB pour avoir l’évolution de l’erreur OOB (Out Of Bag) en fonction du nombre d’arbres construits.
Une fois que vous avez cliqué sur le bouton OK, les calculs commencent puis les résultats sont affichés.
Interpréter les résultats d'une Forêt aléatoire de classification
Les premiers résultats affichés sont le nombre d’observations de l’ensemble d’apprentissage qui ont été supprimées (car comprenaient des valeurs manquantes) et le taux d’erreur OOB. Cette erreur correspond à l’erreur moyenne de classification commise sur chaque échantillon OOB de l’ensemble d’apprentissage.
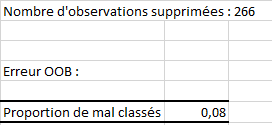
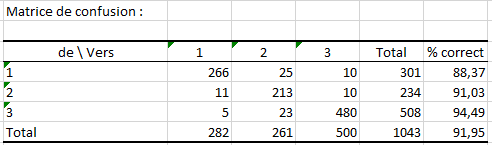
Le tableau qui suit donne la matrice de confusion obtenue sur l’ensemble d'apprentissage. Ces matrices donnent le niveau de performance de notre classifieur (Performances mesurées sur les données OOB). Sur le jeu d'apprentissage, nous avons obtenu 91.95% de réponses correctes.
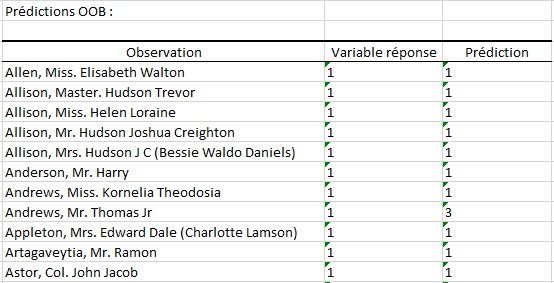
Le second tableau affiche la réponse associée à chaque observation et la classe prédite pour cette dernière (prédiction faite en utilisant uniquement les arbres dans lesquels elle est OOB).
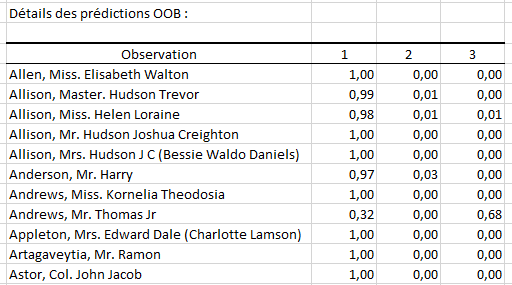
Ensuite, nous avons pour chaque observation de l’ensemble d’apprentissage la probabilité qu’elle a d’appartenir à chacune des classes de la variable réponse (probabilité basée sur les données OOB).
Le tableau suivant affiche pour chaque observation de l’ensemble d’apprentissage le nombre d’arbres dans lesquels elle est OOB.
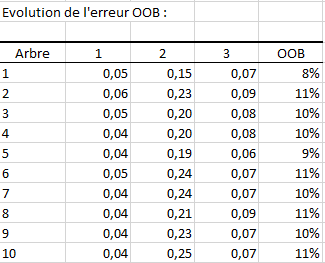
Le dernier tableau affiche l’évolution de l’erreur OOB en fonction du nombre d’arbres. La ligne i du tableau correspond à l’erreur OOB commise en prenant en compte tous les arbres jusqu’au i -ème. En plus de l’erreur OOB on a aussi une colonne par modalité représentant l’évolution de l’erreur commise sur chacune des modalités de la variable réponse.
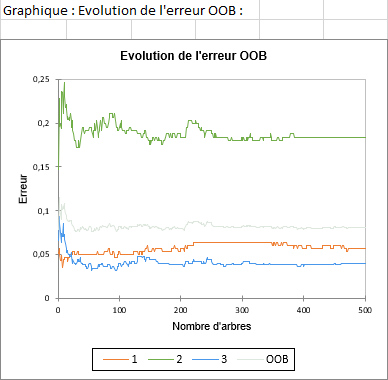
Le graphique qui suit résume l’information contenue dans le tableau précédent.
Cet article vous a t-il été utile ?
- Oui
- Non