Régression quantile dans Excel
Ce tutoriel vous aidera à configurer et à interpréter une régression Quantile dans Excel à l’aide du logiciel XLSTAT.
Jeu de données sur la Régression Quantile
Les données proviennent de : Lewis T. and Taylor L.R. (1967). Introduction to Experimental Ecology, New York : Academic Press, Inc. Elles concernent 237 enfants, décrits par leur sexe, leur âge en mois, leur taille en inch (1 inch = 2.54 cm), et leur poids en livres (1 livre = 0.45 kg).
But de ce tutoriel sur la Régression Quantile
En utilisant la régression quantile, notre but est d'étudier comment le poids varie en fonction du sexe (variable qualitative prenant la valeur f ou m), de la taille et de l'âge de l'enfant, et de vérifier si une relation linéaire a un sens. La Régression Quantile est une méthode proche de la régression linéaire, de l'ANOVA ou encore de l’ANCOVA, faisant aussi partie de la famille GLM (Generalized linear models).
La spécificité de la Régression Quantile par rapport à ces autres méthodes est de fournir une estimation de quantiles conditionnels au lieu d’une moyenne conditionnelle. Ainsi, la Régression Quantile permet une analyse plus fine basée sur l’étude de quantiles.
L’interprétation des coefficients de régression estimés est la même que celle des autres modèles linéaires. Ainsi, les coefficients du modèle de Régression Quantile peuvent être interprétés comme des taux de variation de la variable dépendante lorsqu’un changement d’une unité de la variable explicative considérée se produit.
D’autre part, il est important de noter que, comme pour l’ANCOVA, il est possible de mélanger des variables quantitatives et qualitatives en Régression Quantile. Dans trois autres tutoriels cet exemple est traîté, d’abord avec la Taille seulement (régression linéaire), puis en ajoutant l'Age (ANOVA), et enfin le Sexe (ANCOVA) comme variables explicatives.
Paramétrer une Régression Quantile
Une fois XLSTAT lancé, choisissez la commande XLSTAT / Modélisation des données / Régression (voir ci-dessous).
Une fois le bouton cliqué, la boîte de dialogue correspondant à la Régression Quantile apparaît.
Vous pouvez dès lors sélectionner les données sur la feuille Excel.
- La Variable dépendante correspond à la variable expliquée (ou variable à modéliser), qui est dans ce cas précis le "poids".
- Les variables quantitatives explicatives sont ici la "taille" et l'"âge", tandis que la variable qualitative est le "sexe".
- L'option Libellés des variables est laissée activée car la première ligne des colonnes comprend le nom des variables.
- Les options des autres onglets sont laissées à leur valeur par défaut.
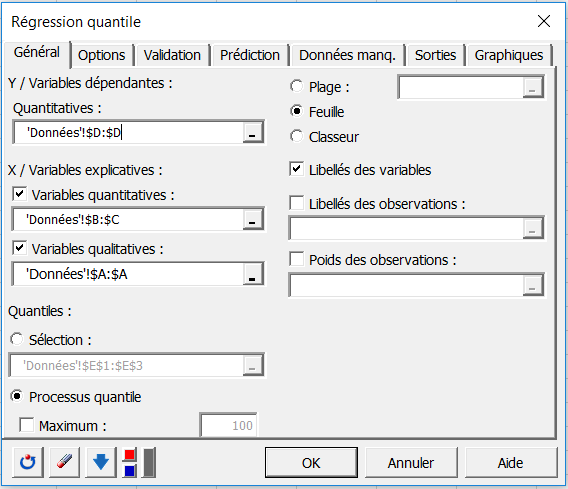 Une fois que vous avez cliqué sur le bouton OK, les calculs commencent puis les résultats sont affichés.
Une fois que vous avez cliqué sur le bouton OK, les calculs commencent puis les résultats sont affichés.
Dans l’exemple suivant, comme on suppose ne pas disposer d’information a priori concernant les quantiles d’intérêt, une analyse en 2 étapes est privilégiée.
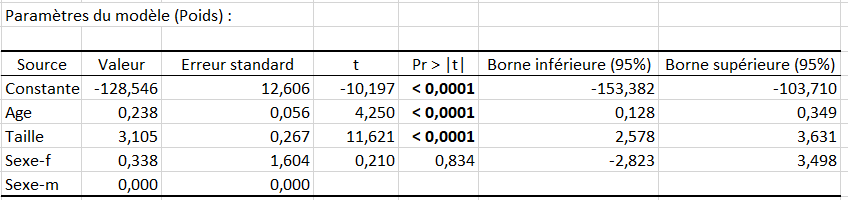
Dans cette étude, on souhaite focaliser notre analyse sur des quantiles pour lesquels les coefficients de régression sont significativement différents de ceux obtenus avec l’ANCOVA. Avant de commencer, rappelons les principaux résultats de l’ANCOVA appliquée à ce jeu de données :
Interpréter les résultats de la première étape d'une Régression Quantile : l’étude du Processus Quantile
Tout d’abord, nous allons lancer une phase « exploratoire » via le Processus Quantile pour obtenir un panorama des valeurs des coefficients pour différents quantiles et ainsi être capables de détecter les quantiles qui nous intéressent plus particulièrement. Dans cette étape préliminaire, seuls des résultats généraux sont générés (davantage d’options sont disponibles dans la seconde étape).
Tout d’abord, on peut remarquer qu’autour de la médiane, les résultats sont du même ordre que ceux de l’ANCOVA (pour la moyenne) :
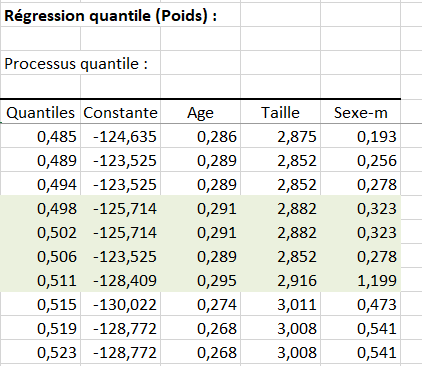
Si, maintenant, on s’intéresse plus en détail aux variables Age et Taille, leur contribution semble plus forte dans l’évaluation du poids des enfants ayant les poids les plus élevés (alpha > 0,9) :

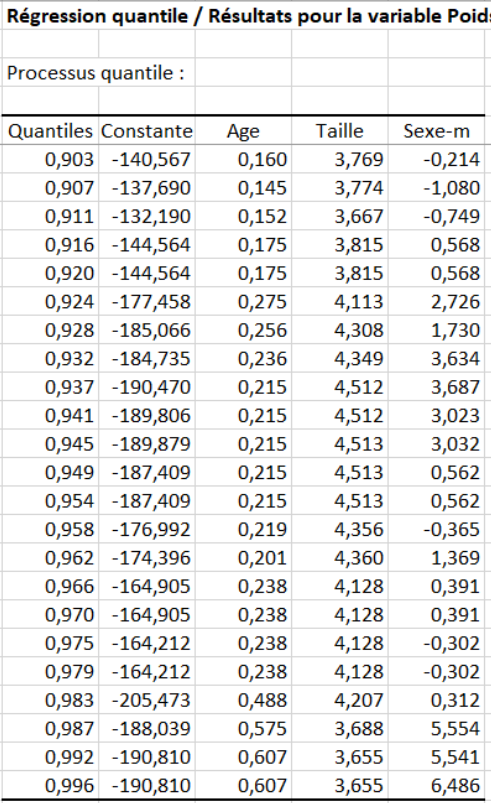
tandis que d’autres résultats de la régression quantile suggèrent que le Sexe a un effet plus important sur le poids des enfants ayant les poids les moins élevés (alpha < 0.1).
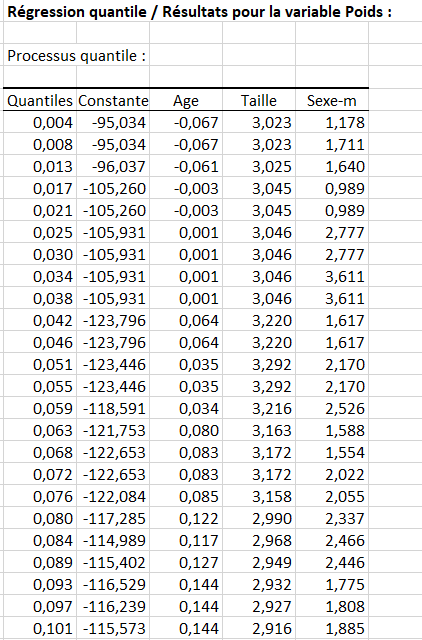
Ainsi, les quantiles d’intérêt appartiennent vraisemblablement aux intervalles [0; 0,1] et [0,9; 1].
On peut facilement confirmer ces impressions en visualisant les graphiques illustratifs affichés en fin d’analyse :
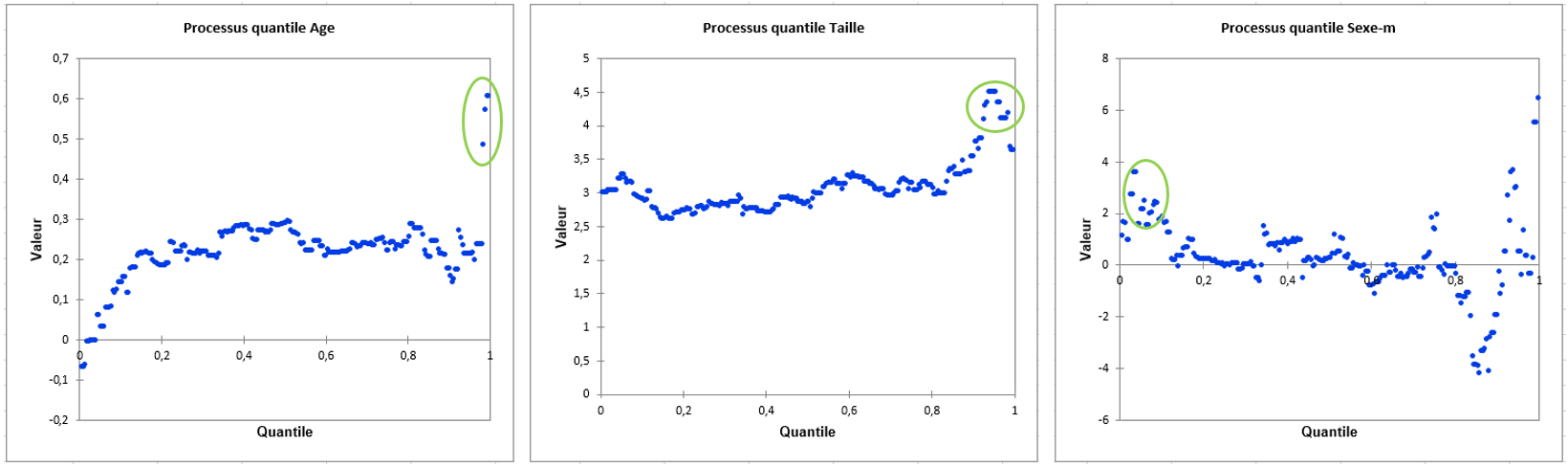
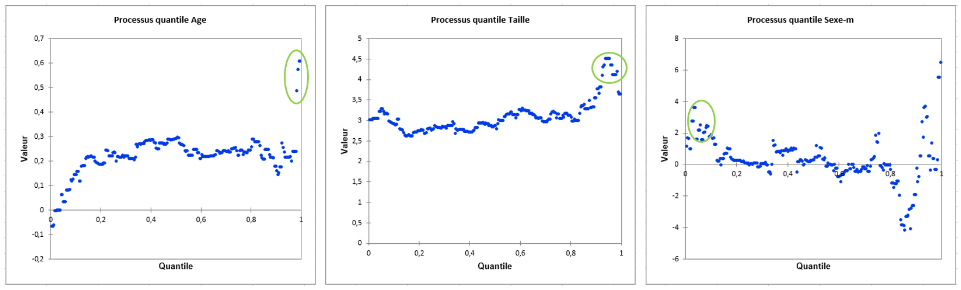
Nous allons alors, dans une seconde étape, étudier plus finement une Sélection de 2 quantiles : 0.95 et 0.05. Ces derniers sont sélectionnés sur la feuille de travail Excel.
Interpréter les résultats de la deuxième étape d'une Régression Quantile : l’étude d’une sélection de quantiles
Le premier tableau de résultats fournit les coefficients d'ajustement du modèle. Le R² (coefficient de détermination) donne une idée du % de variabilité de la variable à modéliser, ici le poids, expliqué par les variables explicatives. Plus ce coefficient est proche de 1, meilleur est le modèle.
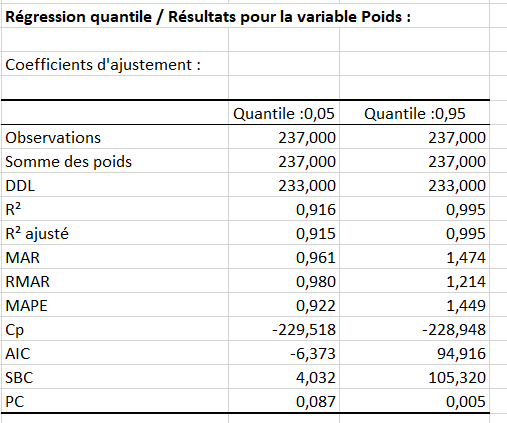
Dans notre cas, 91.6% de la variabilité du Poids est expliquée par la Taille, l'Age et le Sexe. Le reste de la variabilité est dû à des effets (autres variables explicatives) qui n'ont pas été mesurés ou mesurables au cours de l'expérience. Des effets génétiques et nutritifs sont de toute évidence impliqués, mais néanmoins une recherche plus poussée pourrait donner de meilleurs résultats en utilisant des transformations des variables utilisées ici.
Le tableau de significativité du modèle est un résultat qui doit être analysé attentivement (voir ci-dessous). C'est à ce niveau que l'on teste si l'on peut considérer que les variables explicatives sélectionnées (la taille et l'âge) apportent une quantité d'information significative au modèle (hypothèse nulle H0) ou non. En d'autres termes, c'est un moyen de tester si la moyenne de la variable à modéliser (le poids) suffirait à décrire les résultats obtenus ou non.
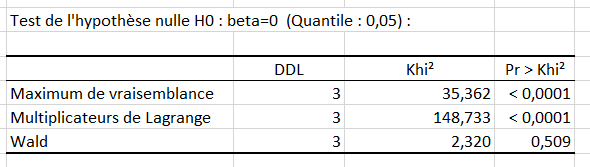
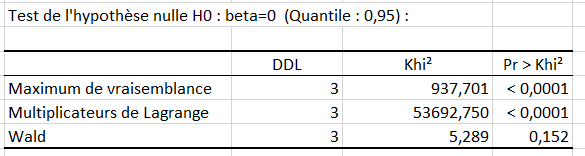
3 tests sont utilisés : Maximum de Vraisemblance, Multiplicateurs de Lagrange et Wald. Etant donné que la probabilité associée au Khi² est dans ce cas inférieure à 0.0001, cela signifie que l'on prend un risque de se tromper de moins de 0.01% en concluant que les variables explicatives apportent une quantité d'information significative au modèle.
Le tableau suivant fournit les détails sur le modèle et est essentiel dès lors que le modèle doit être utilisé pour faire des prévisions, des simulations ou s'il doit être comparé à d'autres résultats.
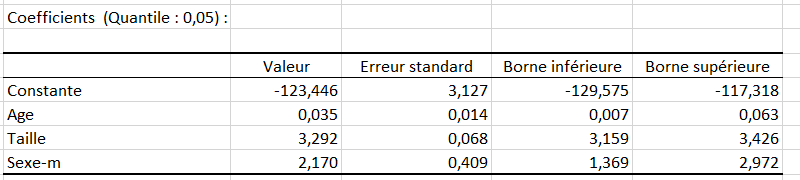
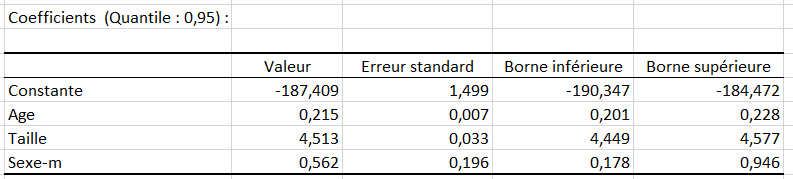
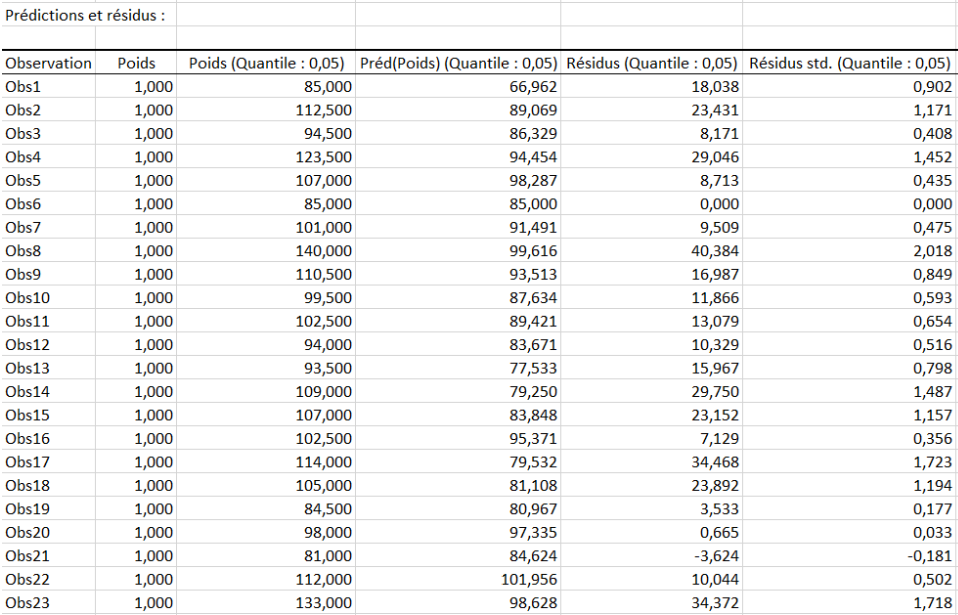
Le tableau qui suit présente une partie de l'analyse des prédictions et des résidus. Les résidus centrés réduits sont également calculés.
Le graphique ci-dessous permet de comparer les prévisions et les valeurs observées pour les deux quantiles considérés.
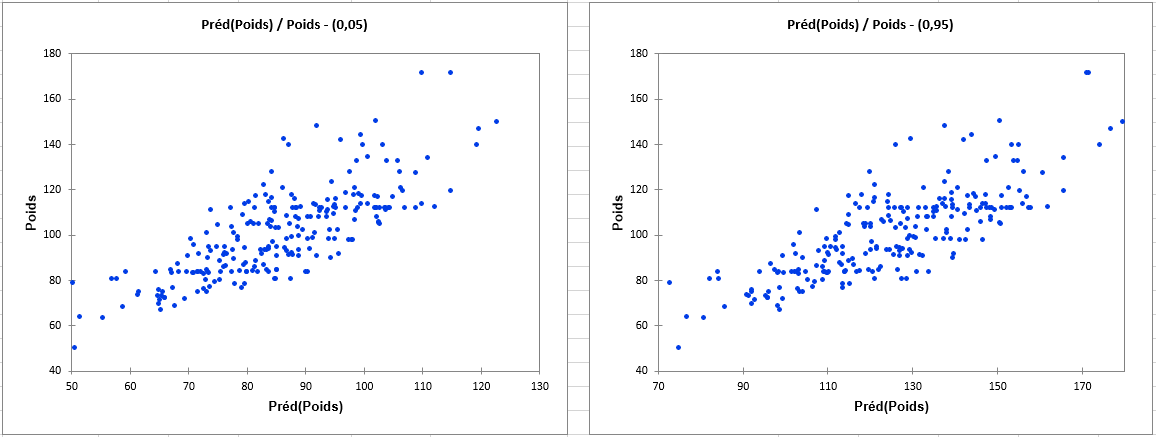
Conclusion pour cette Régression Quantile
En conclusion, la taille, l'âge et le sexe permettent d'expliquer plus de 90% de la variabilité du poids. Une part importante de la variabilité du poids est donc expliquée par le modèle de régression quantile.
Cet article vous a t-il été utile ?
- Oui
- Non