TABLAS DE CLUSTERING MEDIANTE CLUSTATIS EN EXCEL
Este tutorial muestra cómo calcular e interpretar una agrupación de tablas mediante CLUSTATIS en Excel utilizando el software XLSTAT.
Conjunto de datos para ejecutar el método CLUSTATIS Se
Los datos proceden de un estudio de Mapping/Napping proyectivo realizado en Rennes por AGROCAMPUS OUEST. 24 sujetos (panelistas) probaron ocho batidos y luego los colocaron sobre un mantel. Las coordenadas se recopilaron para el análisis STATIS. Si un panelista considera que dos productos son similares, estos últimos se colocan cercanos sobre el mantel, por lo que tienen coordenadas similares. El archivo original se puede obtener con el paquete SensoMineR de R.
Este conjunto de datos también se utiliza en nuestro tutorial sobre STATIS, para analizar batidos directamente sin agrupar por temas.
Objetivo de este tutorial El objetivo aquí es realizar un análisis de datos de tres pasos:- Segmentar las tablas (denominadas aquí configuraciones) de datos, es decir, los sujetos aquí, de acuerdo con sus percepciones de los productos. El método CLUSTATIS se utilizará para crear clases lo más homogéneas posibles.
- Analizar cada clase de temas utilizando el método STATIS para determinar las diferencias en las percepciones de los batidos entre clases.
- Determinar los índices de calidad de la agrupación.
Configurar un análisis CLUSTATIS en XLSTAT
Seleccione el comando XLSTAT/Funciones avanzadas/Análisis de datos sensoriales/ CLUSTATIS (ver más abajo).
Aparece el cuadro de dialogo de CLUSTATIS.
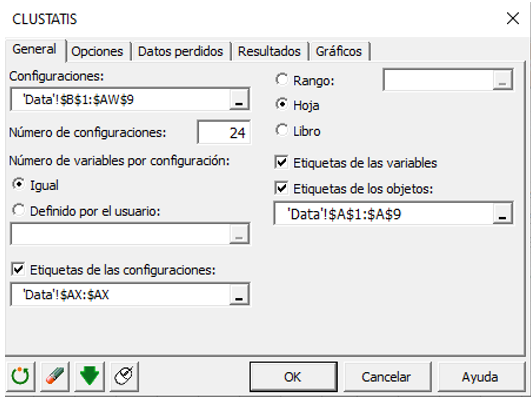
En la pestaña General, seleccione los datos en la hoja de Excel del archivo de demostración que corresponden a las configuraciones (una configuración corresponde aquí al conjunto de coordenadas dadas por un sujeto). Luego se debe ingresar el número de configuraciones. Aquí, hay 24 tablas contiguas correspondientes a los 24 temas.
Como cada configuración tiene 2 variables, podemos hacerle saber a XLSTAT que el número de variables es constante seleccionando la opción Igual. Si el número de variables es diferente para al menos una configuración, debe seleccionar una columna que contenga el número de variables para cada configuración.
Por último, activa las opciones Etiquetas de variable y Etiquetas de objeto (en nuestro caso los batidos).
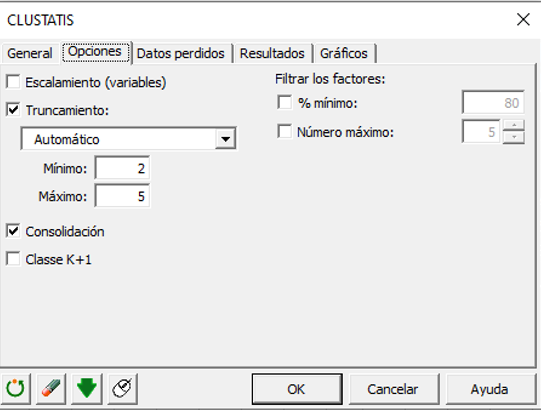
En la pestaña Opciones, optamos por no reducir las variables, ya que dentro de cada configuración, todas las variables están en la misma escala. Decidimos dejar automática la elección del número de clases y aplicar una consolidación de las clases obtenidas por el algoritmo jerárquico para obtener un análisis de conglomerados más preciso.
En la pestaña Gráficos, si selecciona la casilla Mostrar gráficos en los dos primeros ejes, automáticamente tendrá la representación en los 2 primeros ejes factoriales de los diferentes mapas. Si la desmarcas, se abrirá una ventana y podrás elegir tus ejes.
Interpretación de los resultados del análisis CLUSTATIS en Excel usando XLSTAT
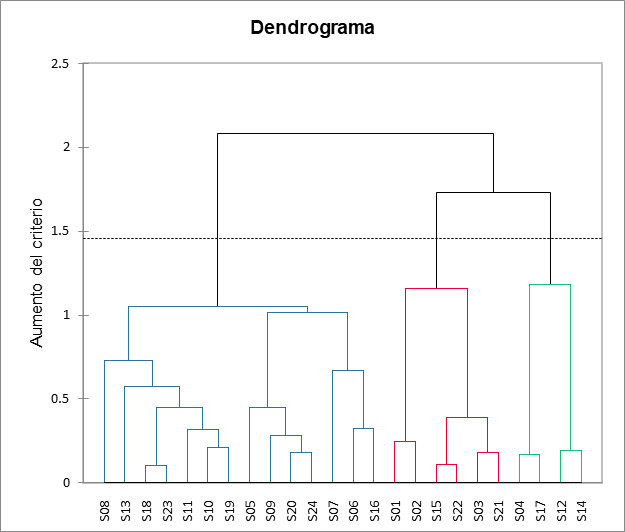
El siguiente gráfico es un dendrograma. Representa cómo funciona el algoritmo para agrupar las configuraciones, luego los grupos de configuraciones. Como puede ver, el algoritmo ha agrupado con éxito todas las configuraciones. La línea de puntos representa el truncamiento automático, lo que lleva a tres grupos.
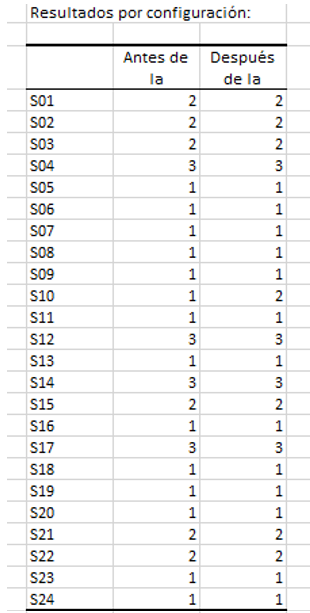
La siguiente tabla muestra las clases de las diferentes configuraciones antes y después de la consolidación. Parece que solo la asignatura 10 cambió de clase con la consolidación.
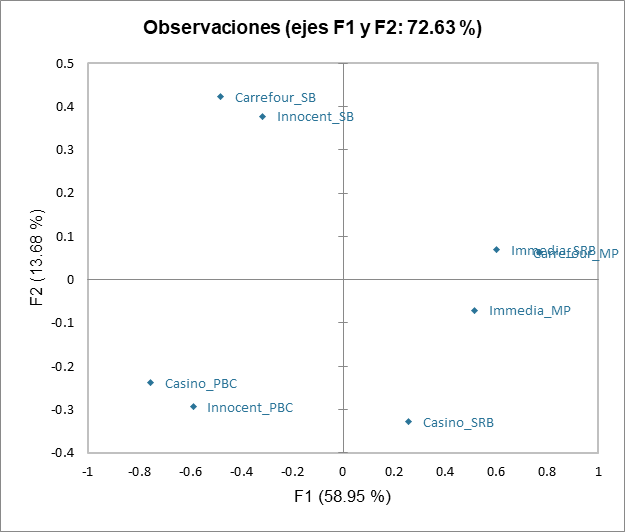
Luego viene el análisis de cada una de las clases construidas. La representación de los objetos (batidos aquí) en cada clase muestra diferencias en la percepción entre las clases de sujetos, especialmente en lo que respecta al batido Carrefour_SB. De hecho, este último es colocado con el batido Innocent_SB por los sujetos de la clase 1, con Innocent_PBC y Casino_PBC por los sujetos de la clase 2, y con Carrefour_MP por los de la clase 3.
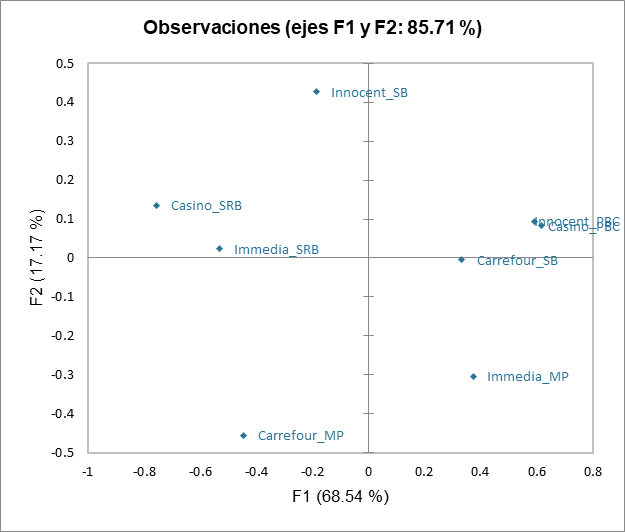
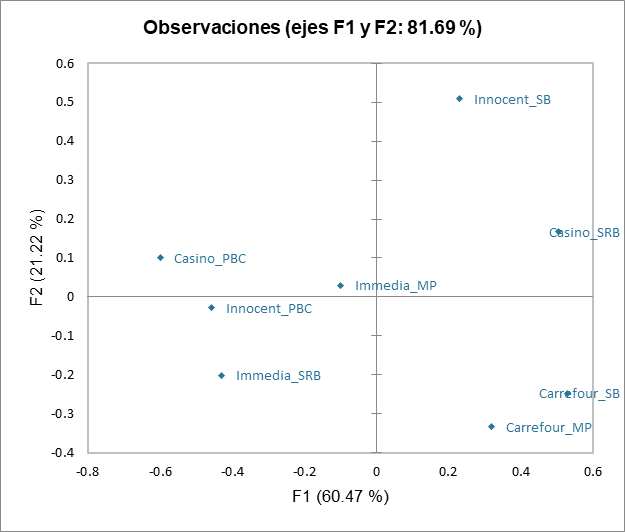
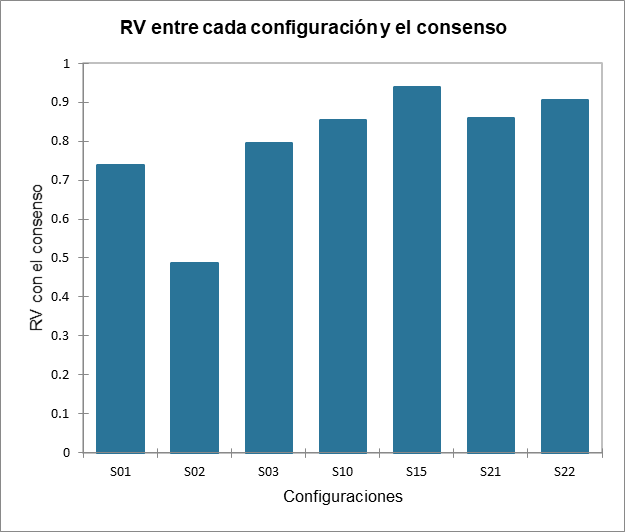
El siguiente gráfico da indicaciones sobre la proximidad de las configuraciones y el consenso de la clase en la que están ubicadas. Estas proximidades están representadas por el coeficiente RV, que es un índice de similitud entre 0 y 1. En la clase 2, podemos observar que el sujeto 2 está mucho más alejado del consenso que los demás, lo que significa que no se ajusta bien a la clase. Su percepción es diferente a todas las clases (ya que ha sido colocado en la clase que más le corresponde por el algoritmo). Este tipo de problema se puede resolver agregando la clase "K + 1" en la pestaña Opciones, que es una clase adicional diseñada para dejar de lado configuraciones atípicas.
Finalmente, los índices de homogeneidad de cada clase permiten evaluar la calidad del análisis de clusters. Cuanto más cerca estén estos índices de 1, más homogéneas serán las clases. Aquí vemos que la clase 1 es un poco menos homogénea que las demás. La homogeneidad global, que es un promedio ponderado de la homogeneidad de cada clase, es bastante correcta. Sin embargo, podría mejorarse con la adición de una clase "K + 1".
¿Ha sido útil este artículo?
- Sí
- No